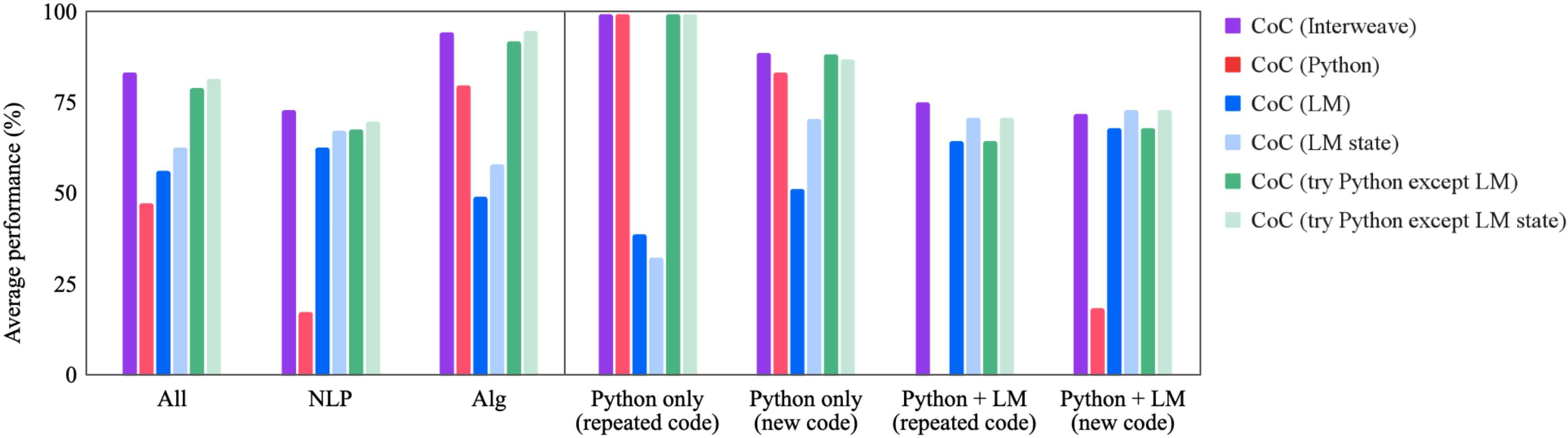
## Bar Chart: Average Performance Comparison
### Overview
The image is a bar chart comparing the average performance (in percentage) of different methods, labeled as "CoC (Interweave)", "CoC (Python)", "CoC (LM)", "CoC (LM state)", "CoC (try Python except LM)", and "CoC (try Python except LM state)", across various tasks or scenarios: "All", "NLP", "Alg", "Python only (repeated code)", "Python only (new code)", "Python + LM (repeated code)", and "Python + LM (new code)".
### Components/Axes
* **Y-axis:** "Average performance (%)", with scale markers at 0, 25, 50, 75, and 100.
* **X-axis:** Categorical labels representing different tasks or scenarios: "All", "NLP", "Alg", "Python only (repeated code)", "Python only (new code)", "Python + LM (repeated code)", and "Python + LM (new code)".
* **Legend:** Located on the right side of the chart, mapping colors to methods:
* Purple: "CoC (Interweave)"
* Red: "CoC (Python)"
* Blue: "CoC (LM)"
* Light Blue: "CoC (LM state)"
* Green: "CoC (try Python except LM)"
* Light Green: "CoC (try Python except LM state)"
### Detailed Analysis or ### Content Details
**1. All**
* CoC (Interweave) (Purple): ~82%
* CoC (Python) (Red): ~47%
* CoC (LM) (Blue): ~54%
* CoC (LM state) (Light Blue): ~66%
* CoC (try Python except LM) (Green): ~78%
* CoC (try Python except LM state) (Light Green): ~82%
**2. NLP**
* CoC (Interweave) (Purple): ~72%
* CoC (Python) (Red): ~15%
* CoC (LM) (Blue): ~60%
* CoC (LM state) (Light Blue): ~65%
* CoC (try Python except LM) (Green): ~68%
* CoC (try Python except LM state) (Light Green): ~70%
**3. Alg**
* CoC (Interweave) (Purple): ~95%
* CoC (Python) (Red): ~78%
* CoC (LM) (Blue): ~48%
* CoC (LM state) (Light Blue): ~55%
* CoC (try Python except LM) (Green): ~97%
* CoC (try Python except LM state) (Light Green): ~98%
**4. Python only (repeated code)**
* CoC (Interweave) (Purple): ~99%
* CoC (Python) (Red): ~99%
* CoC (LM) (Blue): ~35%
* CoC (LM state) (Light Blue): ~30%
* CoC (try Python except LM) (Green): ~99%
* CoC (try Python except LM state) (Light Green): ~99%
**5. Python only (new code)**
* CoC (Interweave) (Purple): ~89%
* CoC (Python) (Red): ~88%
* CoC (LM) (Blue): ~88%
* CoC (LM state) (Light Blue): ~90%
* CoC (try Python except LM) (Green): ~89%
* CoC (try Python except LM state) (Light Green): ~90%
**6. Python + LM (repeated code)**
* CoC (Interweave) (Purple): ~62%
* CoC (Python) (Red): ~10%
* CoC (LM) (Blue): ~62%
* CoC (LM state) (Light Blue): ~72%
* CoC (try Python except LM) (Green): ~62%
* CoC (try Python except LM state) (Light Green): ~72%
**7. Python + LM (new code)**
* CoC (Interweave) (Purple): ~68%
* CoC (Python) (Red): ~12%
* CoC (LM) (Blue): ~68%
* CoC (LM state) (Light Blue): ~70%
* CoC (try Python except LM) (Green): ~68%
* CoC (try Python except LM state) (Light Green): ~70%
### Key Observations
* "CoC (try Python except LM state)" and "CoC (try Python except LM)" generally perform well across all tasks.
* "CoC (Python)" shows lower performance in "NLP", "Python + LM (repeated code)", and "Python + LM (new code)" scenarios.
* "CoC (LM)" has significantly lower performance in "Python only (repeated code)" compared to other scenarios.
* For "Python only (repeated code)", all methods except "CoC (LM)" and "CoC (LM state)" achieve near-perfect performance.
### Interpretation
The bar chart provides a comparative analysis of different methods ("CoC" variants) across various tasks. The performance varies significantly depending on the task and the method used. The "CoC (try Python except LM)" and "CoC (try Python except LM state)" methods generally exhibit high performance, suggesting that excluding the Language Model (LM) in certain Python-based approaches can be beneficial. The lower performance of "CoC (Python)" in specific scenarios indicates potential limitations or inefficiencies in those contexts. The chart highlights the importance of selecting the appropriate method based on the specific task requirements to optimize performance. The near-perfect performance of most methods in "Python only (repeated code)" suggests that repeated code execution benefits from these approaches, while the lower performance of "CoC (LM)" in the same scenario indicates a potential incompatibility or inefficiency when using a Language Model with repeated code.