\n
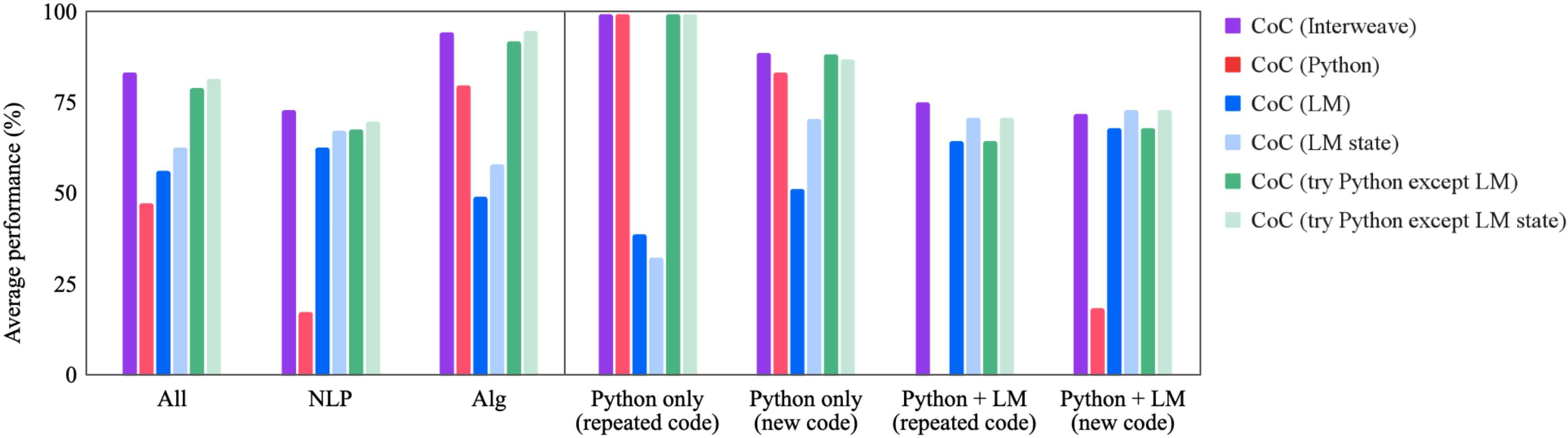
## Bar Chart: Average Performance Comparison of Code Generation Techniques
### Overview
This bar chart compares the average performance (in percentage) of several code generation techniques across different task categories. The techniques are variations of "CoC" (likely Code Completion) utilizing different approaches like Interweave, Python, and Language Models (LM), with and without state management and exception handling. The task categories are "All", "NLP", "Alg", "Python only (repeated code)", "Python only (new code)", "Python + LM (repeated code)", and "Python + LM (new code)".
### Components/Axes
* **X-axis:** Task Category. Categories are: "All", "NLP", "Alg", "Python only (repeated code)", "Python only (new code)", "Python + LM (repeated code)", "Python + LM (new code)".
* **Y-axis:** Average performance (%). Scale ranges from 0 to 100.
* **Legend:** Located in the top-right corner, identifies the different code generation techniques using color-coded bars.
* CoC (Interweave) - Purple
* CoC (Python) - Red
* CoC (LM) - Blue
* CoC (LM state) - Light Blue
* CoC (try Python except LM) - Green
* CoC (try Python except LM state) - Teal
### Detailed Analysis
The chart consists of seven groups of bars, one for each task category. Each group contains six bars, representing the performance of each of the six code generation techniques.
**All:**
* CoC (Interweave): Approximately 82%
* CoC (Python): Approximately 78%
* CoC (LM): Approximately 73%
* CoC (LM state): Approximately 76%
* CoC (try Python except LM): Approximately 88%
* CoC (try Python except LM state): Approximately 85%
**NLP:**
* CoC (Interweave): Approximately 72%
* CoC (Python): Approximately 68%
* CoC (LM): Approximately 63%
* CoC (LM state): Approximately 66%
* CoC (try Python except LM): Approximately 78%
* CoC (try Python except LM state): Approximately 75%
**Alg:**
* CoC (Interweave): Approximately 78%
* CoC (Python): Approximately 74%
* CoC (LM): Approximately 92%
* CoC (LM state): Approximately 88%
* CoC (try Python except LM): Approximately 94%
* CoC (try Python except LM state): Approximately 91%
**Python only (repeated code):**
* CoC (Interweave): Approximately 95%
* CoC (Python): Approximately 92%
* CoC (LM): Approximately 98%
* CoC (LM state): Approximately 96%
* CoC (try Python except LM): Approximately 99%
* CoC (try Python except LM state): Approximately 98%
**Python only (new code):**
* CoC (Interweave): Approximately 85%
* CoC (Python): Approximately 82%
* CoC (LM): Approximately 88%
* CoC (LM state): Approximately 86%
* CoC (try Python except LM): Approximately 91%
* CoC (try Python except LM state): Approximately 89%
**Python + LM (repeated code):**
* CoC (Interweave): Approximately 65%
* CoC (Python): Approximately 62%
* CoC (LM): Approximately 68%
* CoC (LM state): Approximately 66%
* CoC (try Python except LM): Approximately 72%
* CoC (try Python except LM state): Approximately 70%
**Python + LM (new code):**
* CoC (Interweave): Approximately 63%
* CoC (Python): Approximately 60%
* CoC (LM): Approximately 66%
* CoC (LM state): Approximately 64%
* CoC (try Python except LM): Approximately 69%
* CoC (try Python except LM state): Approximately 67%
### Key Observations
* The "try Python except LM" technique consistently achieves the highest performance across all task categories.
* Performance is generally highest for tasks involving "repeated code" and lowest for tasks involving "new code" when combining Python and LM.
* The "LM" based approaches (CoC (LM) and CoC (LM state)) perform better on the "Alg" task compared to "All", "NLP", "Python only", and "Python + LM" tasks.
* The "Interweave" and "Python" techniques show relatively stable performance across different task categories.
### Interpretation
The data suggests that a hybrid approach of "try Python except LM" is the most effective code generation technique across a variety of tasks. This likely indicates that leveraging Python for its strengths and falling back on a Language Model when Python fails is a robust strategy. The superior performance on tasks with "repeated code" suggests that these techniques excel at recognizing and replicating existing patterns. The performance dip when generating "new code" implies a challenge in creative problem-solving or understanding complex requirements. The strong performance of LM-based approaches on the "Alg" task could be due to the LM's ability to learn and generalize algorithmic patterns. The chart highlights the importance of combining different code generation strategies to maximize overall performance and adaptability. The consistent performance of the "Interweave" and "Python" techniques suggests they provide a solid baseline, while the "try...except" approach adds a layer of resilience and adaptability.