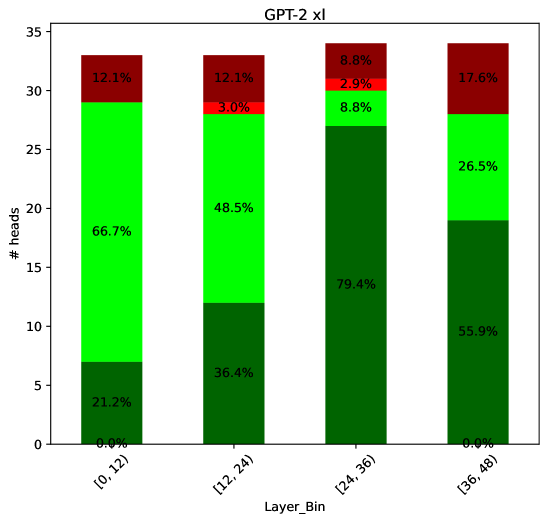
## Bar Chart: GPT-2 xl Head Distribution by Layer Bin
### Overview
The chart visualizes the distribution of attention heads across four layer bins ([0,12], [12,24], [24,36], [36,48]) in the GPT-2 xl model. Each bar is segmented into three categories: "Heads" (green), "Heads (merged)" (dark green), and "Heads (unmerged)" (red). The y-axis represents the number of heads, with percentages indicating proportional distribution within each bin.
### Components/Axes
- **X-axis**: Layer bins labeled as [0,12], [12,24], [24,36], [36,48]
- **Y-axis**: "# heads" (0–35)
- **Legend**:
- Green: "Heads" (66.7% in [0,12], decreasing to 26.5% in [36,48])
- Dark green: "Heads (merged)" (21.2% in [0,12], peaking at 79.4% in [24,36])
- Red: "Heads (unmerged)" (12.1% in [0,12], increasing to 17.6% in [36,48])
### Detailed Analysis
1. **Layer Bin [0,12]**:
- Heads: 66.7% (21.2 heads)
- Heads (merged): 21.2% (6.7 heads)
- Heads (unmerged): 12.1% (3.8 heads)
2. **Layer Bin [12,24]**:
- Heads: 48.5% (15.5 heads)
- Heads (merged): 36.4% (11.6 heads)
- Heads (unmerged): 15.1% (4.8 heads)
3. **Layer Bin [24,36]**:
- Heads: 8.8% (2.8 heads)
- Heads (merged): 79.4% (25.4 heads)
- Heads (unmerged): 2.9% (0.9 heads)
4. **Layer Bin [36,48]**:
- Heads: 26.5% (8.5 heads)
- Heads (merged): 55.9% (18.0 heads)
- Heads (unmerged): 17.6% (5.6 heads)
### Key Observations
- **Merged Heads Dominance**: The dark green segment ("Heads (merged)") peaks at 79.4% in the [24,36] bin, suggesting a concentration of merged heads in mid-layers.
- **Unmerged Heads Increase**: The red segment ("Heads (unmerged)") grows steadily from 12.1% to 17.6%, indicating rising fragmentation in later layers.
- **Heads Reduction**: The green segment ("Heads") declines from 66.7% to 8.8%, showing fewer total heads in higher layers.
### Interpretation
The data reveals a structural shift in attention mechanisms across GPT-2 xl layers:
1. **Early Layers ([0,12])**: High proportion of individual heads (66.7%) with moderate merging (21.2%) and fragmentation (12.1%).
2. **Mid-Layers ([24,36])**: Dominance of merged heads (79.4%) suggests optimized attention patterns, potentially improving computational efficiency.
3. **Late Layers ([36,48])**: Resurgence of unmerged heads (17.6%) alongside reduced total heads (26.5%) may indicate architectural adjustments to balance expressiveness and efficiency.
This pattern aligns with transformer design principles, where mid-layers often consolidate attention for hierarchical processing, while later layers reintroduce granularity for fine-grained tasks. The absence of unmerged heads in the [24,36] bin highlights a critical transition point in the model's attention architecture.