## Heatmap: Accuracy Breakdown
### Overview
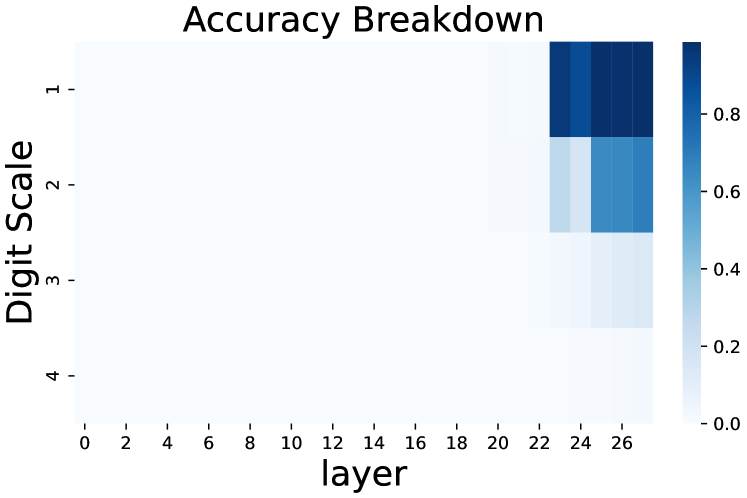
The image is a heatmap titled "Accuracy Breakdown". The heatmap visualizes the accuracy of a model across different layers (x-axis) and digit scales (y-axis). The color intensity represents the accuracy value, with darker blue indicating higher accuracy and lighter blue indicating lower accuracy.
### Components/Axes
* **Title:** Accuracy Breakdown
* **X-axis:** "layer" with tick marks at 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, and 26.
* **Y-axis:** "Digit Scale" with tick marks at 1, 2, 3, and 4.
* **Colorbar:** A vertical colorbar on the right side of the heatmap, ranging from 0.0 (lightest blue) to 0.8 (darkest blue), with tick marks at 0.0, 0.2, 0.4, 0.6, and 0.8.
### Detailed Analysis
The heatmap shows accuracy values for different combinations of "layer" and "Digit Scale".
* **Digit Scale 1:** Accuracy is approximately 0.8 for layers 22, 24, and 26.
* **Digit Scale 2:** Accuracy is approximately 0.6 for layer 22, 0.7 for layer 24, and 0.8 for layer 26.
* **Digit Scale 3:** Accuracy is approximately 0.4 for layer 22, 0.5 for layer 24, and 0.5 for layer 26.
* **Digit Scale 4:** Accuracy is approximately 0.0 for layers 0 through 26.
For layers 0 through 20, the accuracy is approximately 0.0 for digit scales 1, 2, and 3.
### Key Observations
* Accuracy generally increases with the layer number, especially for layers 22, 24, and 26.
* Accuracy decreases as the digit scale increases. Digit scale 4 has the lowest accuracy across all layers.
* The model performs significantly better on digit scales 1, 2, and 3 compared to digit scale 4.
### Interpretation
The heatmap suggests that the model's accuracy is highly dependent on both the layer and the digit scale. The later layers (22, 24, 26) seem to be more effective in extracting relevant features, leading to higher accuracy. The poor performance on digit scale 4 indicates that the model struggles to accurately classify digits at that scale, potentially due to the features being less discriminative or the model not being trained adequately on that scale. The model does not appear to learn anything until layer 22.