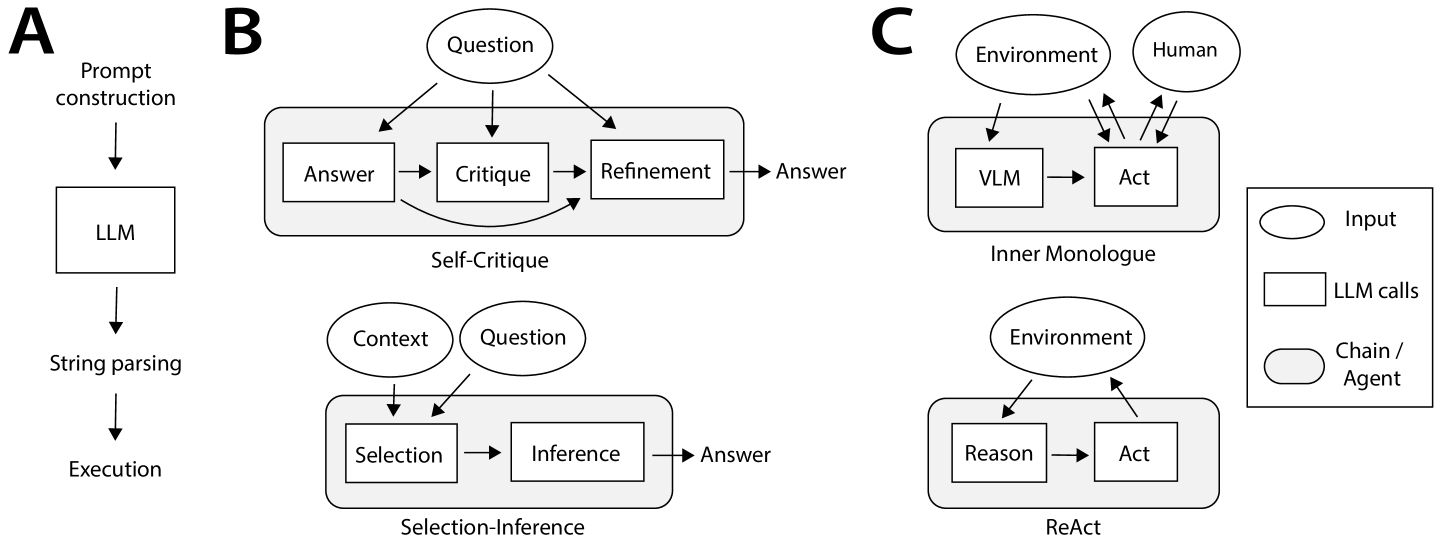
## Diagram: Multi-Stage LLM Processing Framework
### Overview
The image depicts a technical workflow diagram illustrating three distinct LLM-based processing architectures: **Prompt Construction**, **Self-Critique**, and **Inner Monologue/ReAct**. Each section represents a different approach to handling input, reasoning, and output generation.
### Components/Axes
#### Section A: Prompt Construction
- **Components**:
- **LLM** (Large Language Model)
- **String parsing**
- **Execution**
- **Flow**:
- Input → LLM → String parsing → Execution
#### Section B: Self-Critique
- **Components**:
- **Question** (input)
- **Answer** (initial response)
- **Critique** (evaluation of answer)
- **Refinement** (improvement of answer)
- **Flow**:
- Question → Answer → Critique → Refinement → Answer (loop)
#### Section C: Inner Monologue/ReAct
- **Subcomponents**:
- **Inner Monologue**:
- **Environment** (external context)
- **Human** (user input)
- **VLM** (Vision-Language Model)
- **Act** (action execution)
- **ReAct**:
- **Environment** (external context)
- **Reason** (logical reasoning)
- **Act** (action execution)
- **Legend**:
- **Input** (circle)
- **LLM calls** (rectangle)
- **Chain/Agent** (circle)
### Detailed Analysis
#### Section A: Prompt Construction
- The process begins with **Prompt construction**, which feeds into an **LLM**. The LLM's output is parsed as a **String**, which is then **Executed** (e.g., code execution or API calls).
#### Section B: Self-Critique
- A **Question** is answered by the LLM, producing an **Answer**. This answer is then **Critiqued** (e.g., for accuracy, coherence) and **Refined** to improve quality. The refined answer loops back to the **Answer** stage, enabling iterative improvement.
#### Section C: Inner Monologue/ReAct
- **Inner Monologue**:
- The **Environment** and **Human** provide context. The **VLM** processes visual or multimodal input, leading to an **Act** (e.g., tool use or decision).
- **ReAct**:
- The **Environment** informs **Reasoning**, which directly leads to an **Act**. This emphasizes a reactive, environment-driven workflow.
### Key Observations
1. **Iterative Improvement**: Section B emphasizes self-critique and refinement, suggesting a focus on accuracy.
2. **Multimodal Interaction**: Section C integrates **VLM** and **Human** inputs, indicating support for complex, context-aware tasks.
3. **Action-Oriented Workflows**: Both **Inner Monologue** and **ReAct** prioritize **Act** as the final output, highlighting actionable outcomes.
### Interpretation
The diagram contrasts three LLM-driven strategies:
- **Prompt Construction** (A) is linear and task-specific.
- **Self-Critique** (B) introduces feedback loops for quality assurance.
- **Inner Monologue/ReAct** (C) emphasizes adaptability, combining reasoning with environmental interaction.
The **ReAct** approach (C) aligns with modern AI agent frameworks, where reasoning and action are tightly coupled. The **Self-Critique** mechanism (B) could reduce hallucinations by iteratively refining outputs. The **VLM** in Section C suggests multimodal capabilities, enabling applications like visual question answering or robotics.
The legend clarifies that **LLM calls** are distinct from **Chain/Agent** workflows, which may involve external tools or APIs. This diagram likely represents a framework for building robust, context-aware LLM systems.