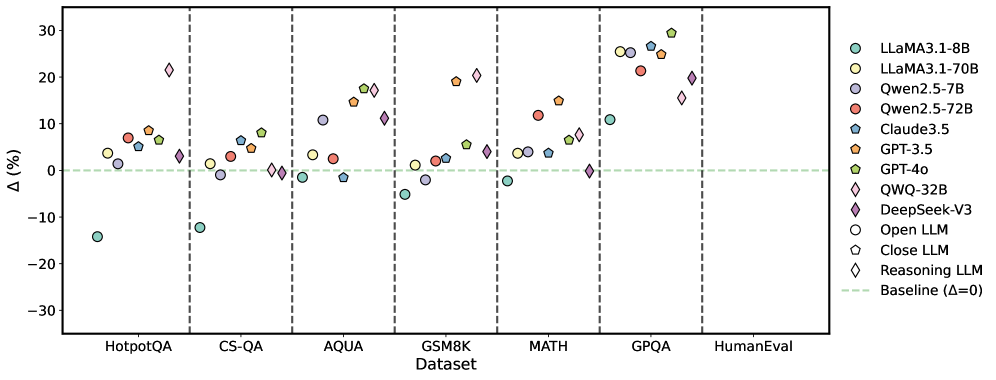
\n
## Scatter Plot: Performance Comparison of Large Language Models
### Overview
This scatter plot compares the performance of several Large Language Models (LLMs) across six different datasets. The y-axis represents the percentage difference (Δ (%)) in performance relative to a baseline, and the x-axis represents the dataset name. Each LLM is represented by a unique marker and color.
### Components/Axes
* **X-axis:** Dataset - with markers for HotpotQA, CS-QA, AQUA, GSM8K, MATH, GPQA, and HumanEval.
* **Y-axis:** Δ (%) - Percentage difference in performance. Scale ranges from approximately -30% to 30%.
* **Legend (Top-Right):**
* LLaMA3-1-8B (Light Blue Circle)
* LLaMA3-1-70B (Light Orange Circle)
* Qwen2.5-7B (Light Grey Circle)
* Qwen2.5-72B (Red Circle)
* Claude3.5 (Dark Turquoise Diamond)
* GPT-3.5 (Dark Orange Triangle)
* GPT-4o (Dark Green Square)
* QWQ-32B (Purple Diamond)
* DeepSeek-V3 (Dark Purple Hexagon)
* Open LLM (White Circle)
* Close LLM (Light Green Triangle)
* Reasoning LLM (Light Blue Diamond)
* Baseline (Δ=0) (Horizontal Dashed Green Line)
### Detailed Analysis
The plot shows the performance variation of each LLM across the datasets. The baseline is indicated by a horizontal dashed green line at Δ = 0%.
* **HotpotQA:**
* LLaMA3-1-8B: Approximately +5%
* LLaMA3-1-70B: Approximately +8%
* Qwen2.5-7B: Approximately +2%
* Qwen2.5-72B: Approximately +5%
* Claude3.5: Approximately +10%
* GPT-3.5: Approximately +5%
* GPT-4o: Approximately +10%
* QWQ-32B: Approximately +15%
* DeepSeek-V3: Approximately +10%
* Open LLM: Approximately -15%
* Close LLM: Approximately -10%
* Reasoning LLM: Approximately -5%
* **CS-QA:**
* LLaMA3-1-8B: Approximately -5%
* LLaMA3-1-70B: Approximately -2%
* Qwen2.5-7B: Approximately -8%
* Qwen2.5-72B: Approximately -5%
* Claude3.5: Approximately +5%
* GPT-3.5: Approximately +2%
* GPT-4o: Approximately +8%
* QWQ-32B: Approximately +10%
* DeepSeek-V3: Approximately +5%
* Open LLM: Approximately -10%
* Close LLM: Approximately -5%
* Reasoning LLM: Approximately 0%
* **AQUA:**
* LLaMA3-1-8B: Approximately +5%
* LLaMA3-1-70B: Approximately +10%
* Qwen2.5-7B: Approximately +2%
* Qwen2.5-72B: Approximately +5%
* Claude3.5: Approximately +10%
* GPT-3.5: Approximately +5%
* GPT-4o: Approximately +15%
* QWQ-32B: Approximately +20%
* DeepSeek-V3: Approximately +10%
* Open LLM: Approximately -5%
* Close LLM: Approximately 0%
* Reasoning LLM: Approximately +5%
* **GSM8K:**
* LLaMA3-1-8B: Approximately 0%
* LLaMA3-1-70B: Approximately +5%
* Qwen2.5-7B: Approximately -5%
* Qwen2.5-72B: Approximately 0%
* Claude3.5: Approximately +10%
* GPT-3.5: Approximately +5%
* GPT-4o: Approximately +15%
* QWQ-32B: Approximately +15%
* DeepSeek-V3: Approximately +10%
* Open LLM: Approximately -10%
* Close LLM: Approximately -5%
* Reasoning LLM: Approximately +5%
* **MATH:**
* LLaMA3-1-8B: Approximately +5%
* LLaMA3-1-70B: Approximately +10%
* Qwen2.5-7B: Approximately -5%
* Qwen2.5-72B: Approximately 0%
* Claude3.5: Approximately +10%
* GPT-3.5: Approximately +5%
* GPT-4o: Approximately +20%
* QWQ-32B: Approximately +15%
* DeepSeek-V3: Approximately +10%
* Open LLM: Approximately -10%
* Close LLM: Approximately -5%
* Reasoning LLM: Approximately +5%
* **GPQA:**
* LLaMA3-1-8B: Approximately +10%
* LLaMA3-1-70B: Approximately +15%
* Qwen2.5-7B: Approximately +5%
* Qwen2.5-72B: Approximately +10%
* Claude3.5: Approximately +15%
* GPT-3.5: Approximately +10%
* GPT-4o: Approximately +25%
* QWQ-32B: Approximately +20%
* DeepSeek-V3: Approximately +15%
* Open LLM: Approximately 0%
* Close LLM: Approximately +5%
* Reasoning LLM: Approximately +10%
* **HumanEval:**
* LLaMA3-1-8B: Approximately +10%
* LLaMA3-1-70B: Approximately +15%
* Qwen2.5-7B: Approximately +5%
* Qwen2.5-72B: Approximately +10%
* Claude3.5: Approximately +15%
* GPT-3.5: Approximately +10%
* GPT-4o: Approximately +20%
* QWQ-32B: Approximately +15%
* DeepSeek-V3: Approximately +10%
* Open LLM: Approximately 0%
* Close LLM: Approximately +5%
* Reasoning LLM: Approximately +10%
### Key Observations
* GPT-4o consistently outperforms other models across all datasets, often achieving the highest percentage difference.
* QWQ-32B and DeepSeek-V3 generally perform well, often close to GPT-4o.
* Open LLMs and Close LLMs consistently underperform compared to the baseline on most datasets.
* The performance difference between LLaMA3-1-8B and LLaMA3-1-70B is noticeable, with the larger model generally performing better.
* Qwen2.5-7B consistently shows lower performance compared to Qwen2.5-72B.
### Interpretation
The data suggests that model size and architecture significantly impact performance on these datasets. GPT-4o's consistent superiority indicates a strong overall capability. The underperformance of Open LLMs and Close LLMs suggests they may require further development or fine-tuning to achieve competitive results. The consistent improvement from smaller to larger models within the same family (e.g., LLaMA3) highlights the benefits of scaling model size. The variation in performance across datasets indicates that different LLMs excel in different areas, suggesting the importance of selecting the appropriate model for a specific task. The baseline (Δ=0) provides a crucial reference point for evaluating the relative performance of each model. The spread of data points for each model indicates the variability in performance across the datasets, highlighting the need for robust evaluation across a diverse set of benchmarks.