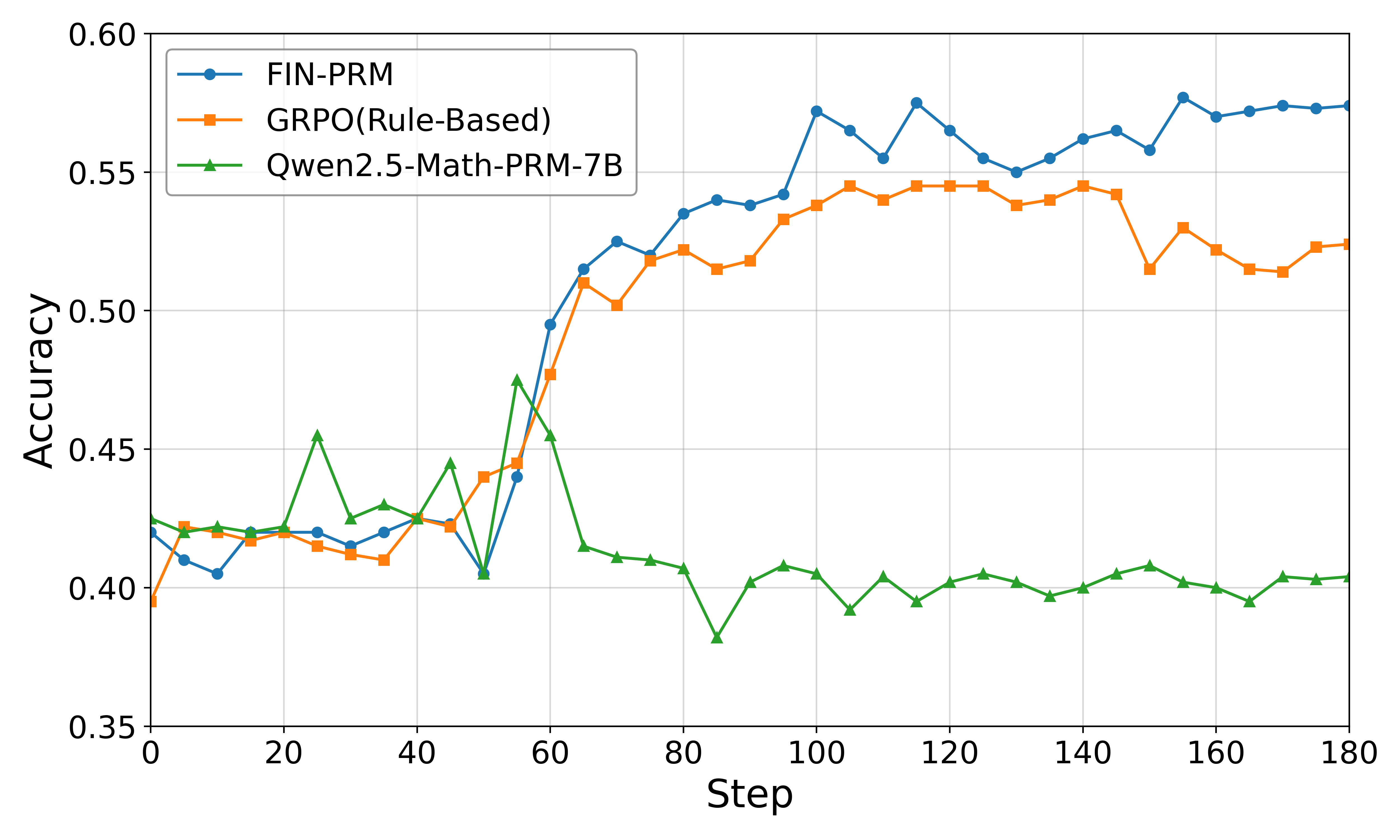
## Line Graph: Algorithm Accuracy Comparison Over Steps
### Overview
The image is a line graph comparing the accuracy of three algorithms—FIN-PRM, GRPO(Rule-Based), and Gwen2.5-Math-PRM-7B—across 180 incremental steps. The y-axis represents accuracy (0.35–0.60), and the x-axis represents steps (0–180). The legend is positioned in the top-left corner, with distinct colors for each algorithm: blue (FIN-PRM), orange (GRPO), and green (Gwen2.5).
### Components/Axes
- **X-axis (Step)**: Labeled "Step," ranging from 0 to 180 in increments of 20.
- **Y-axis (Accuracy)**: Labeled "Accuracy," ranging from 0.35 to 0.60 in increments of 0.05.
- **Legend**: Top-left corner, with color-coded labels:
- Blue circle: FIN-PRM
- Orange square: GRPO(Rule-Based)
- Green triangle: Gwen2.5-Math-PRM-7B
### Detailed Analysis
1. **FIN-PRM (Blue Line)**:
- Starts at ~0.42 at step 0.
- Gradually increases, peaking at ~0.58 around step 100.
- Stabilizes between ~0.55–0.58 from step 120 onward.
- Notable fluctuations: Dips slightly at step 60 (~0.50) and step 140 (~0.56).
2. **GRPO(Rule-Based) (Orange Line)**:
- Begins at ~0.40 at step 0.
- Rises steadily to ~0.54 by step 100.
- Experiences minor declines after step 120, stabilizing at ~0.52–0.54 by step 180.
- Sharp drop at step 150 (~0.52) followed by recovery.
3. **Gwen2.5-Math-PRM-7B (Green Line)**:
- Starts at ~0.42 at step 0.
- Peaks at ~0.48 around step 50.
- Declines sharply to ~0.38 at step 80.
- Remains flat between ~0.40–0.42 from step 100 onward.
### Key Observations
- **FIN-PRM** consistently outperforms the other algorithms, particularly after step 100.
- **GRPO** shows moderate improvement but lags behind FIN-PRM, with a notable dip at step 150.
- **Gwen2.5** exhibits the most volatility, with a sharp decline after step 50 and no recovery.
### Interpretation
The data suggests that **FIN-PRM** is the most robust algorithm, maintaining high accuracy across all steps. **GRPO** demonstrates steady but suboptimal performance, while **Gwen2.5**’s early peak and subsequent decline indicate potential instability or overfitting in later stages. The divergence between FIN-PRM and Gwen2.5 after step 100 highlights differences in algorithmic efficiency or adaptability. The GRPO dip at step 150 may reflect a specific challenge or limitation in its rule-based framework. Overall, FIN-PRM’s sustained performance makes it the preferred choice for this task.