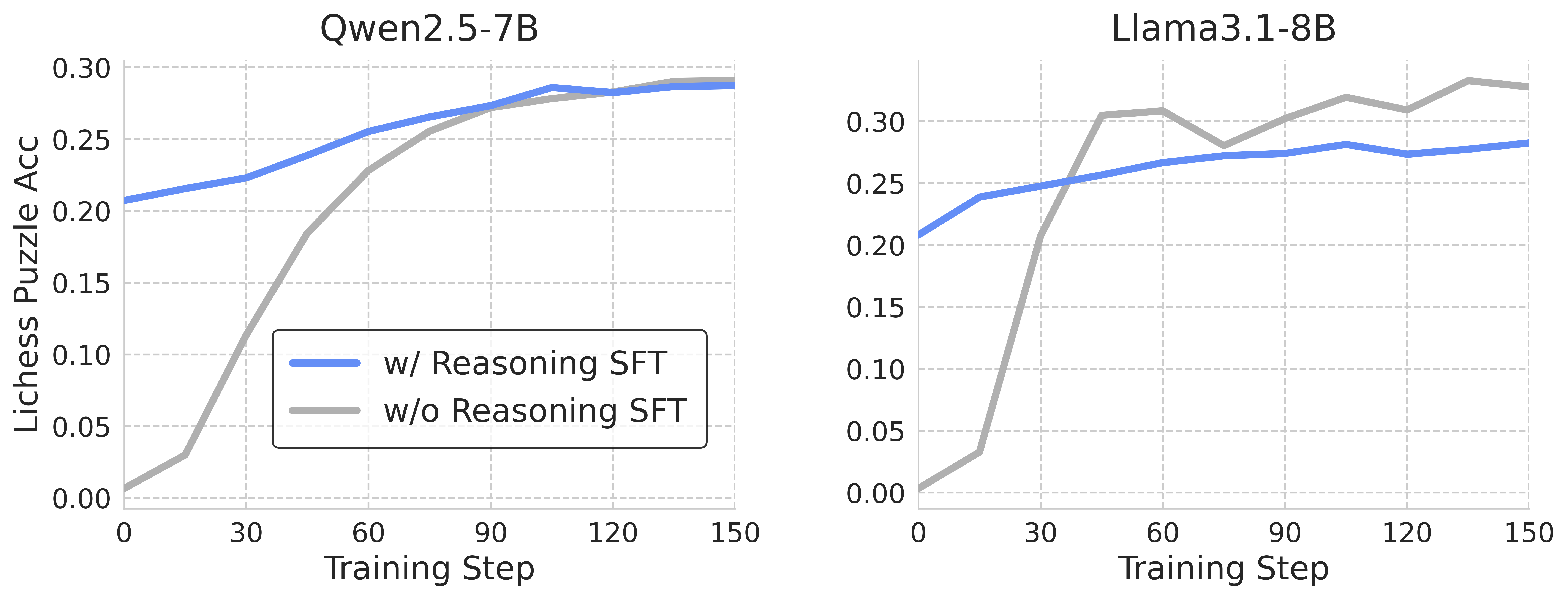
## Line Graphs: Lichess Puzzle Accuracy vs. Training Step for Qwen2.5-7B and Llama3.1-8B
### Overview
The image presents two line graphs comparing the performance of two language models, Qwen2.5-7B and Llama3.1-8B, on a Lichess puzzle accuracy task. Each graph plots the accuracy against the training step, with two lines representing training with and without reasoning (SFT - Supervised Fine-Tuning).
### Components/Axes
* **Titles:**
* Left Graph: Qwen2.5-7B
* Right Graph: Llama3.1-8B
* **Y-axis (Lichess Puzzle Acc):**
* Label: Lichess Puzzle Acc
* Scale: 0.00 to 0.30, with increments of 0.05 (0.00, 0.05, 0.10, 0.15, 0.20, 0.25, 0.30)
* **X-axis (Training Step):**
* Label: Training Step
* Scale: 0 to 150, with increments of 30 (0, 30, 60, 90, 120, 150)
* **Legend (located in the center of the two graphs):**
* Blue line: w/ Reasoning SFT
* Gray line: w/o Reasoning SFT
### Detailed Analysis
**Left Graph: Qwen2.5-7B**
* **Blue Line (w/ Reasoning SFT):**
* Trend: Generally increasing, with a slight plateau after 90 training steps.
* Data Points:
* 0 Training Step: ~0.21
* 30 Training Step: ~0.22
* 60 Training Step: ~0.25
* 90 Training Step: ~0.28
* 120 Training Step: ~0.28
* 150 Training Step: ~0.29
* **Gray Line (w/o Reasoning SFT):**
* Trend: Rapidly increasing initially, then plateaus after 90 training steps.
* Data Points:
* 0 Training Step: ~0.01
* 30 Training Step: ~0.07
* 60 Training Step: ~0.19
* 90 Training Step: ~0.28
* 120 Training Step: ~0.29
* 150 Training Step: ~0.29
**Right Graph: Llama3.1-8B**
* **Blue Line (w/ Reasoning SFT):**
* Trend: Increasing, then plateaus after 60 training steps.
* Data Points:
* 0 Training Step: ~0.21
* 30 Training Step: ~0.24
* 60 Training Step: ~0.26
* 90 Training Step: ~0.27
* 120 Training Step: ~0.27
* 150 Training Step: ~0.29
* **Gray Line (w/o Reasoning SFT):**
* Trend: Rapid initial increase, followed by fluctuations and a plateau.
* Data Points:
* 0 Training Step: ~0.01
* 30 Training Step: ~0.31
* 60 Training Step: ~0.28
* 90 Training Step: ~0.31
* 120 Training Step: ~0.33
* 150 Training Step: ~0.33
### Key Observations
* For both models, training with reasoning (blue line) generally results in higher initial accuracy.
* The "w/o Reasoning SFT" (gray line) for both models shows a steeper initial increase in accuracy compared to "w/ Reasoning SFT" (blue line).
* Llama3.1-8B (right graph) shows more fluctuation in the "w/o Reasoning SFT" line compared to Qwen2.5-7B (left graph).
* Both models reach similar accuracy levels at the end of the training steps, regardless of whether reasoning is included in the SFT.
### Interpretation
The graphs suggest that while training with reasoning (SFT) provides a better starting point for both models, training without reasoning catches up as the training progresses. The fluctuations in Llama3.1-8B's "w/o Reasoning SFT" line might indicate instability or sensitivity to the training data. The similar final accuracy levels suggest that both models can achieve comparable performance on the Lichess puzzle task, regardless of the initial training approach. The data indicates that reasoning SFT is more important in the early stages of training.