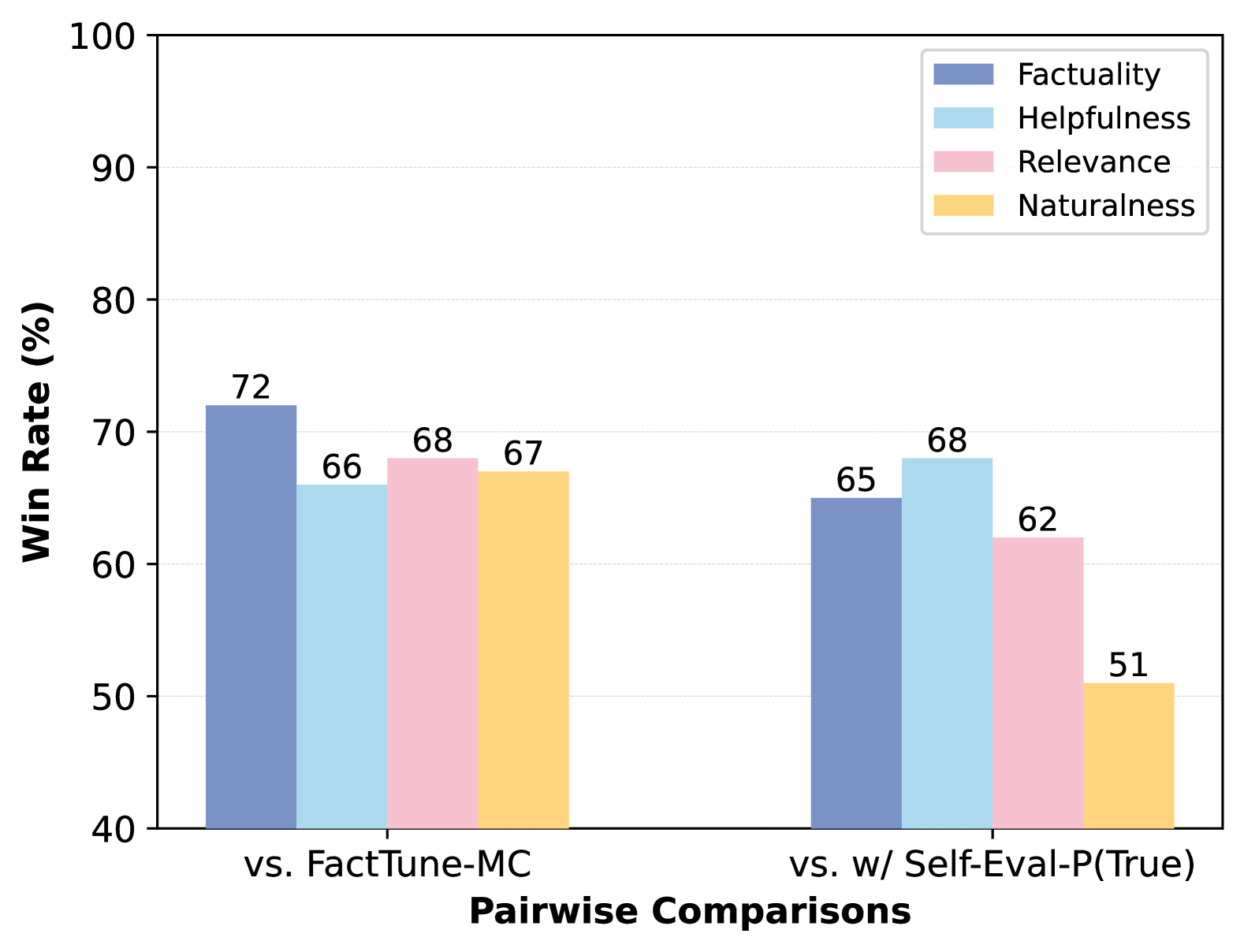
## Bar Chart: Pairwise Comparison of Model Performance
### Overview
The image is a bar chart comparing the performance of two models, "FactTune-MC" and "w/ Self-Eval-P(True)", across four metrics: Factuality, Helpfulness, Relevance, and Naturalness. The y-axis represents the "Win Rate (%)", ranging from 40% to 100%. The x-axis represents the "Pairwise Comparisons" between the two models.
### Components/Axes
* **Title:** None explicitly present in the image.
* **X-axis:** "Pairwise Comparisons" with two categories: "vs. FactTune-MC" and "vs. w/ Self-Eval-P(True)".
* **Y-axis:** "Win Rate (%)" ranging from 40 to 100, with tick marks at intervals of 10 (40, 50, 60, 70, 80, 90, 100).
* **Legend:** Located at the top-right of the chart, indicating the color-coding for each metric:
* Factuality: Blue
* Helpfulness: Light Blue
* Relevance: Pink
* Naturalness: Yellow
### Detailed Analysis
**Group 1: vs. FactTune-MC**
* **Factuality (Blue):** Win Rate = 72%
* **Helpfulness (Light Blue):** Win Rate = 66%
* **Relevance (Pink):** Win Rate = 68%
* **Naturalness (Yellow):** Win Rate = 67%
**Group 2: vs. w/ Self-Eval-P(True)**
* **Factuality (Blue):** Win Rate = 65%
* **Helpfulness (Light Blue):** Win Rate = 68%
* **Relevance (Pink):** Win Rate = 62%
* **Naturalness (Yellow):** Win Rate = 51%
### Key Observations
* For the "vs. FactTune-MC" comparison, Factuality has the highest win rate (72%), while Helpfulness has the lowest (66%).
* For the "vs. w/ Self-Eval-P(True)" comparison, Helpfulness has the highest win rate (68%), while Naturalness has the lowest (51%).
* The win rates for Factuality, Helpfulness, and Relevance are higher when compared against FactTune-MC than when compared against w/ Self-Eval-P(True).
* Naturalness has a significantly lower win rate (51%) when compared against w/ Self-Eval-P(True) compared to when compared against FactTune-MC (67%).
### Interpretation
The bar chart illustrates a comparative analysis of model performance based on pairwise comparisons. When comparing against FactTune-MC, the model performs relatively well across all four metrics. However, when comparing against w/ Self-Eval-P(True), there is a noticeable drop in performance, particularly in Naturalness. This suggests that the "w/ Self-Eval-P(True)" model excels in generating more natural responses compared to the other model. The data indicates that FactTune-MC is stronger in Factuality, while w/ Self-Eval-P(True) is stronger in Naturalness. The other two metrics, Helpfulness and Relevance, show a smaller difference between the two models.