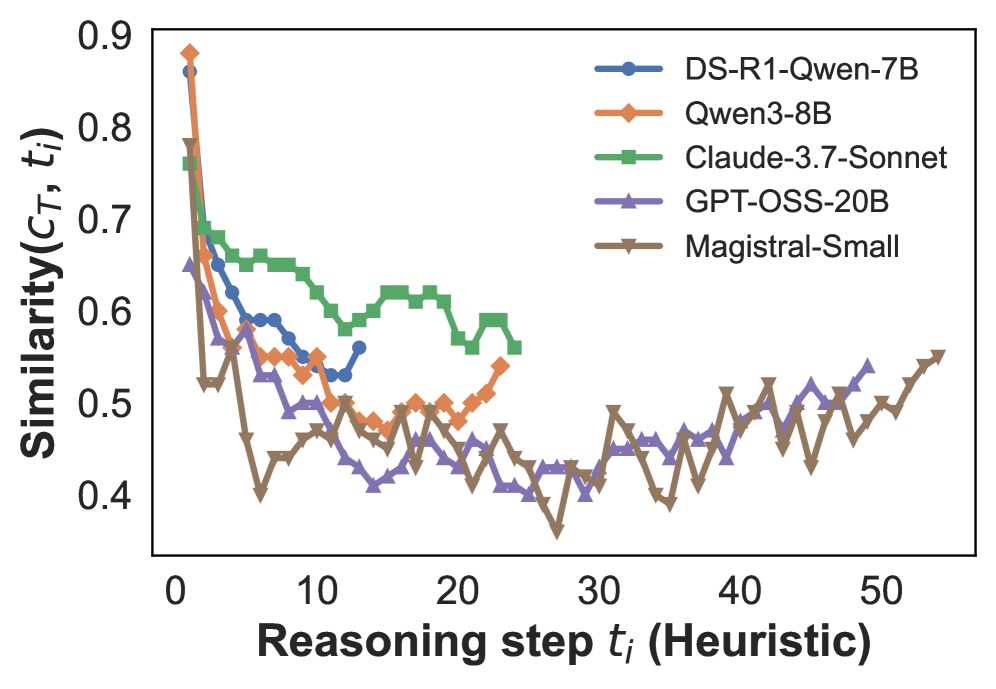
## Line Graph: Similarity vs. Reasoning step (Heuristic)
### Overview
The graph depicts the similarity metric (c_T, t_i) across heuristic reasoning steps (t_i) for five AI models. The y-axis ranges from 0.4 to 0.9, while the x-axis spans 0 to 50 reasoning steps. Five distinct data series are plotted with unique markers and colors.
### Components/Axes
- **X-axis**: "Reasoning step t_i (Heuristic)" (0–50, integer increments)
- **Y-axis**: "Similarity(c_T, t_i)" (0.4–0.9, 0.1 increments)
- **Legend**: Located in the top-right corner, mapping colors/markers to models:
- Blue circles: DS-R1-Qwen-7B
- Orange diamonds: Qwen3-8B
- Green squares: Claude-3.7-Sonnet
- Purple triangles: GPT-OSS-20B
- Brown triangles: Magistral-Small
### Detailed Analysis
1. **DS-R1-Qwen-7B (Blue Circles)**:
- Starts at ~0.85 similarity at t=0
- Sharp decline to ~0.55 by t=10
- Stabilizes with minor fluctuations (~0.55–0.6) thereafter
2. **Qwen3-8B (Orange Diamonds)**:
- Begins at ~0.8 similarity at t=0
- Drops to ~0.5 by t=10
- Exhibits moderate volatility (~0.5–0.6) until t=30, then stabilizes
3. **Claude-3.7-Sonnet (Green Squares)**:
- Initial similarity ~0.75 at t=0
- Gradual decline to ~0.6 by t=10
- Maintains stable performance (~0.6–0.7) with minor oscillations
4. **GPT-OSS-20B (Purple Triangles)**:
- Starts at ~0.65 similarity at t=0
- Sharp drop to ~0.45 by t=10
- High volatility (~0.4–0.55) throughout, with no clear stabilization
5. **Magistral-Small (Brown Triangles)**:
- Initial similarity ~0.6 at t=0
- Steep decline to ~0.4 by t=10
- Persistent fluctuations (~0.4–0.55) with no stabilization
### Key Observations
- **Initial Drop**: All models show a significant similarity decline within the first 10 steps, suggesting an adaptation phase.
- **Stability Variance**: Claude-3.7-Sonnet demonstrates the most stable performance post-t=10, while GPT-OSS-20B remains highly volatile.
- **Long-term Performance**: DS-R1-Qwen-7B and Qwen3-8B achieve moderate stabilization (~0.55–0.6), whereas Magistral-Small and GPT-OSS-20B show persistent instability.
- **Outlier Behavior**: GPT-OSS-20B exhibits the most erratic pattern, with sharp dips and recoveries (e.g., ~0.45 at t=15, ~0.55 at t=25).
### Interpretation
The data suggests that model architecture and training significantly influence reasoning stability. Claude-3.7-Sonnet’s consistent performance implies robust heuristic adaptation, while GPT-OSS-20B’s volatility may indicate overfitting or insufficient generalization. The initial similarity drop across all models could reflect computational overhead in early reasoning stages. Notably, DS-R1-Qwen-7B’s rapid stabilization aligns with its larger parameter count (7B), suggesting scalability benefits. The absence of convergence toward higher similarity values implies inherent limitations in heuristic reasoning across these models, warranting further investigation into optimization strategies.