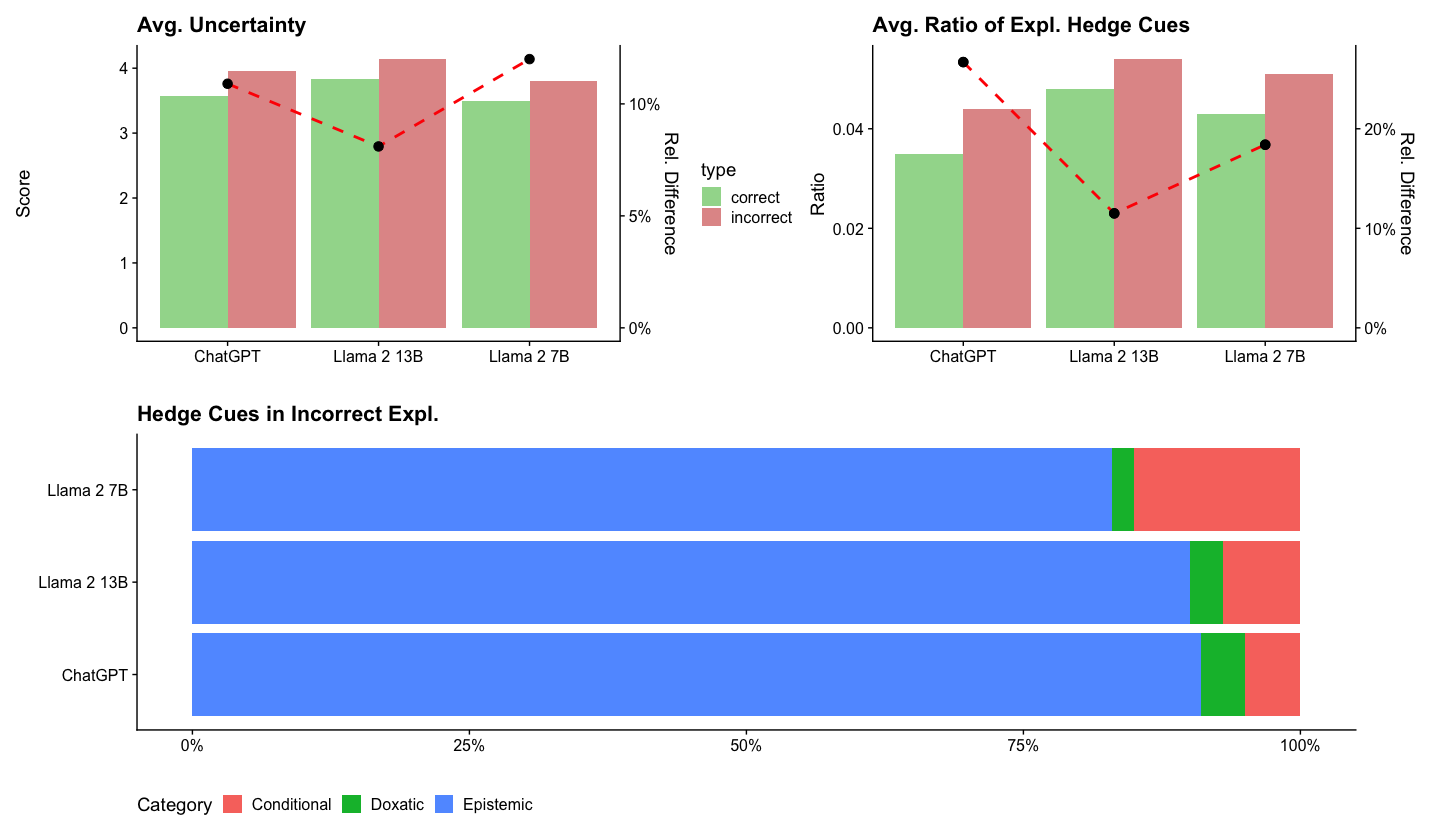
## [Chart Set]: Analysis of Uncertainty and Hedge Cues in Language Model Explanations
### Overview
The image contains three distinct charts analyzing the behavior of three language models (ChatGPT, Llama 2 13B, Llama 2 7B) regarding uncertainty and the use of "hedge cues" in their explanations. The top section contains two dual-axis bar charts comparing "correct" vs. "incorrect" explanations. The bottom section contains a horizontal stacked bar chart detailing the types of hedge cues found specifically in incorrect explanations.
### Components/Axes
**Top-Left Chart: "Avg. Uncertainty"**
* **Primary Y-Axis (Left):** Label: "Score". Scale: 0 to 4, with increments of 1.
* **Secondary Y-Axis (Right):** Label: "Rel. Difference". Scale: 0% to 10%, with increments of 5%.
* **X-Axis:** Categories: "ChatGPT", "Llama 2 13B", "Llama 2 7B".
* **Legend:** Located between the two top charts. Title: "type". Categories: "correct" (green bar), "incorrect" (red bar).
* **Data Series:**
1. **Bar Series:** Paired green ("correct") and red ("incorrect") bars for each model.
2. **Line Series:** A red dashed line with black circular markers, plotted against the right "Rel. Difference" axis.
**Top-Right Chart: "Avg. Ratio of Expl. Hedge Cues"**
* **Primary Y-Axis (Left):** Label: "Ratio". Scale: 0.00 to 0.04, with increments of 0.02.
* **Secondary Y-Axis (Right):** Label: "Rel. Difference". Scale: 0% to 20%, with increments of 10%.
* **X-Axis:** Categories: "ChatGPT", "Llama 2 13B", "Llama 2 7B".
* **Legend:** Shared with the top-left chart (green="correct", red="incorrect").
* **Data Series:**
1. **Bar Series:** Paired green ("correct") and red ("incorrect") bars for each model.
2. **Line Series:** A red dashed line with black circular markers, plotted against the right "Rel. Difference" axis.
**Bottom Chart: "Hedge Cues in Incorrect Expl."**
* **Y-Axis:** Categories: "Llama 2 7B", "Llama 2 13B", "ChatGPT" (listed from top to bottom).
* **X-Axis:** Label: Percentage scale from 0% to 100%, with markers at 0%, 25%, 50%, 75%, 100%.
* **Legend:** Located at the bottom. Title: "Category". Categories: "Conditional" (red), "Doxastic" (green), "Epistemic" (blue).
* **Data Series:** A single horizontal stacked bar for each model, segmented by color according to the legend.
### Detailed Analysis
**1. Avg. Uncertainty Chart (Top-Left)**
* **Trend Verification:** For all three models, the red "incorrect" bar is taller than the green "correct" bar, indicating higher average uncertainty scores for incorrect explanations. The red dashed line (Rel. Difference) shows a "V" shape, dipping at Llama 2 13B.
* **Data Points (Approximate):**
* **ChatGPT:** Correct Score ≈ 3.6, Incorrect Score ≈ 3.9. Rel. Difference ≈ 8%.
* **Llama 2 13B:** Correct Score ≈ 3.8, Incorrect Score ≈ 4.1. Rel. Difference ≈ 7%.
* **Llama 2 7B:** Correct Score ≈ 3.5, Incorrect Score ≈ 3.8. Rel. Difference ≈ 11% (highest relative difference).
**2. Avg. Ratio of Expl. Hedge Cues Chart (Top-Right)**
* **Trend Verification:** For all three models, the red "incorrect" bar is taller than the green "correct" bar, indicating a higher ratio of hedge cues in incorrect explanations. The red dashed line (Rel. Difference) shows a "check mark" shape, dipping at Llama 2 13B.
* **Data Points (Approximate):**
* **ChatGPT:** Correct Ratio ≈ 0.035, Incorrect Ratio ≈ 0.043. Rel. Difference ≈ 23% (highest relative difference).
* **Llama 2 13B:** Correct Ratio ≈ 0.048, Incorrect Ratio ≈ 0.055. Rel. Difference ≈ 11%.
* **Llama 2 7B:** Correct Ratio ≈ 0.043, Incorrect Ratio ≈ 0.051. Rel. Difference ≈ 19%.
**3. Hedge Cues in Incorrect Expl. Chart (Bottom)**
* **Component Isolation:** Each horizontal bar represents 100% of the hedge cues used in that model's incorrect explanations.
* **Data Distribution (Approximate percentages):**
* **Llama 2 7B:** Epistemic (Blue) ≈ 82%, Doxastic (Green) ≈ 3%, Conditional (Red) ≈ 15%.
* **Llama 2 13B:** Epistemic (Blue) ≈ 88%, Doxastic (Green) ≈ 4%, Conditional (Red) ≈ 8%.
* **ChatGPT:** Epistemic (Blue) ≈ 90%, Doxastic (Green) ≈ 5%, Conditional (Red) ≈ 5%.
### Key Observations
1. **Consistent Pattern:** Across all models, incorrect explanations are associated with both higher average uncertainty scores and a higher ratio of hedge cues compared to correct explanations.
2. **Model Comparison:** Llama 2 13B shows the highest absolute scores and ratios for both correct and incorrect explanations. However, ChatGPT and Llama 2 7B often show a larger *relative* increase (Rel. Difference) in these metrics when moving from correct to incorrect explanations.
3. **Hedge Cue Composition:** In incorrect explanations, the vast majority of hedge cues are "Epistemic" (related to knowledge or belief) across all models. "Conditional" cues are the second most common, while "Doxastic" cues (related to opinion) are rare.
4. **Inverse Relationship in Hedge Cue Ratio:** While Llama 2 13B has the highest absolute ratio of hedge cues, it has the smallest relative difference between correct and incorrect explanations. ChatGPT has the largest relative difference.
### Interpretation
The data suggests a strong correlation between a language model's expression of uncertainty (both in self-reported scores and in linguistic hedging) and the factual correctness of its explanations. Incorrect answers are not just wrong; they are delivered with measurably more cautious, qualified, or uncertain language.
The dominance of "Epistemic" hedge cues (e.g., "I think," "It might be") in incorrect explanations indicates that models may be using language that frames knowledge as tentative or belief-based when they are less confident or incorrect. The lower use of "Doxastic" cues suggests models rarely frame incorrect answers as mere opinion.
The variation between models is notable. Llama 2 13B appears to use more hedging language overall, but the *change* in its behavior between correct and incorrect states is less pronounced than for ChatGPT or Llama 2 7B. This could imply different internal confidence calibration or different linguistic strategies for expressing uncertainty. The charts collectively provide a multi-faceted view of how model "uncertainty" manifests both as an internal score and as a communicative style, linking it directly to output quality.