## Bar Charts: Model Performance Metrics
### Overview
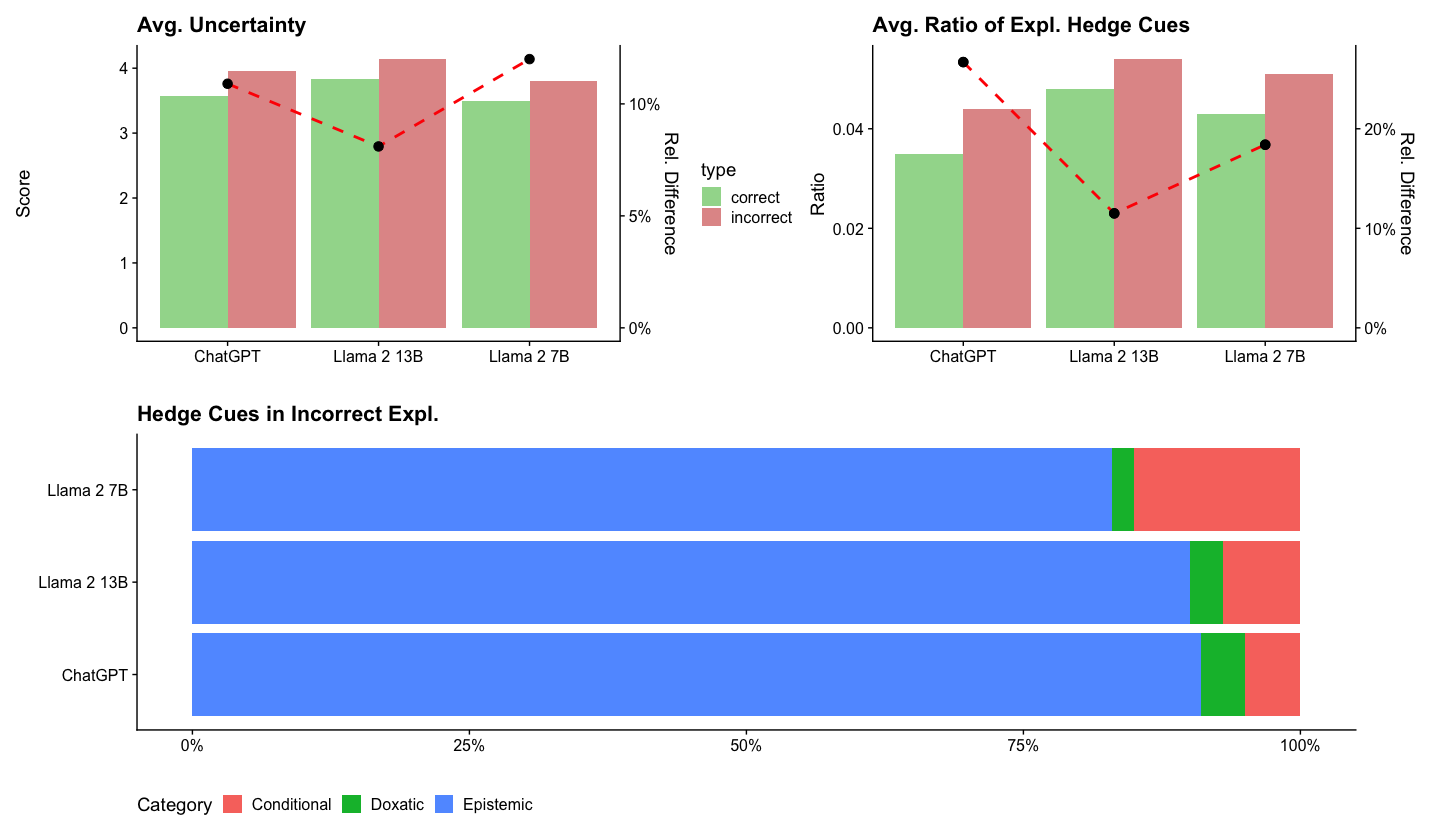
The image contains three bar charts comparing model performance across three AI systems: ChatGPT, Llama 2 13B, and Llama 2 7B. The charts focus on uncertainty metrics, explanation hedge cues, and their distribution in incorrect explanations.
### Components/Axes
1. **Top-Left Chart: Avg. Uncertainty**
- **Y-axis**: Score (0–4)
- **X-axis**: Models (ChatGPT, Llama 2 13B, Llama 2 7B)
- **Legend**: Green = correct, Red = incorrect
- **Data Points**:
- ChatGPT: Correct = 3.5, Incorrect = 3.8
- Llama 2 13B: Correct = 3.8, Incorrect = 4.1
- Llama 2 7B: Correct = 3.4, Incorrect = 3.7
- **Trend**: Red bars (incorrect) consistently exceed green bars (correct) by ~10% relative difference.
2. **Top-Right Chart: Avg. Ratio of Expl. Hedge Cues**
- **Y-axis**: Ratio (0–0.04)
- **X-axis**: Models (same as above)
- **Legend**: Green = correct, Red = incorrect
- **Data Points**:
- ChatGPT: Correct = 0.03, Incorrect = 0.04
- Llama 2 13B: Correct = 0.035, Incorrect = 0.045
- Llama 2 7B: Correct = 0.032, Incorrect = 0.042
- **Trend**: Red bars (incorrect) exceed green bars by ~20% relative difference.
3. **Bottom Chart: Hedge Cues in Incorrect Expl.**
- **Y-axis**: Models (same as above)
- **X-axis**: Percentage (0–100%)
- **Legend**: Red = Conditional, Green = Doxastic, Blue = Epistemic
- **Data Points**:
- ChatGPT: Epistemic = 75%, Conditional = 20%, Doxastic = 5%
- Llama 2 13B: Epistemic = 80%, Conditional = 15%, Doxastic = 5%
- Llama 2 7B: Epistemic = 78%, Conditional = 18%, Doxastic = 4%
### Key Observations
1. **Uncertainty Trends**:
- Llama 2 13B shows the highest uncertainty in incorrect answers (4.1 vs. 3.8 correct).
- ChatGPT has the lowest uncertainty in correct answers (3.5 vs. 3.8 incorrect).
2. **Hedge Cue Ratios**:
- All models exhibit ~20% higher hedge cue ratios in incorrect explanations.
- Llama 2 13B has the highest ratio (0.045 incorrect vs. 0.035 correct).
3. **Hedge Cue Distribution**:
- Epistemic hedges dominate incorrect explanations (75–80%).
- Doxastic hedges are minimal (4–5%).
- Conditional hedges vary slightly (15–20%).
### Interpretation
1. **Uncertainty and Hedge Cues**:
- Higher uncertainty in incorrect answers correlates with increased use of hedge cues (e.g., "might," "could").
- Llama 2 13B’s elevated uncertainty and hedge cue ratio suggest it is more cautious in uncertain scenarios.
2. **Hedge Cue Types**:
- Epistemic hedges (e.g., "I think") dominate, indicating models express uncertainty about factual claims.
- Doxastic hedges (e.g., "I believe") are rare, suggesting models rarely express personal conviction in incorrect answers.
- Conditional hedges (e.g., "If X, then Y") are moderately present, reflecting logical constraints in incorrect reasoning.
3. **Model Differences**:
- Llama 2 13B outperforms smaller models in uncertainty metrics but shows similar hedge cue patterns.
- ChatGPT’s lower uncertainty in correct answers may reflect better calibration in accurate responses.
### Spatial Grounding
- **Legends**: All legends are positioned on the right side of their respective charts.
- **Data Alignment**: Bars are aligned horizontally, with red (incorrect) bars consistently taller than green (correct) bars in the first two charts.
- **Stacked Bars**: The bottom chart uses vertical stacking to show proportional distributions of hedge cue types.
### Final Notes
The data highlights trade-offs between model size, uncertainty, and explanation strategies. Llama 2 13B’s higher uncertainty and hedge cue usage may reflect its larger parameter count, while ChatGPT’s lower uncertainty suggests more confident (but potentially less nuanced) responses. The dominance of epistemic hedges in incorrect explanations underscores a common strategy for models to signal uncertainty when uncertain.