\n
## Chart: Risk Tolerance Responses by Model Tuning
### Overview
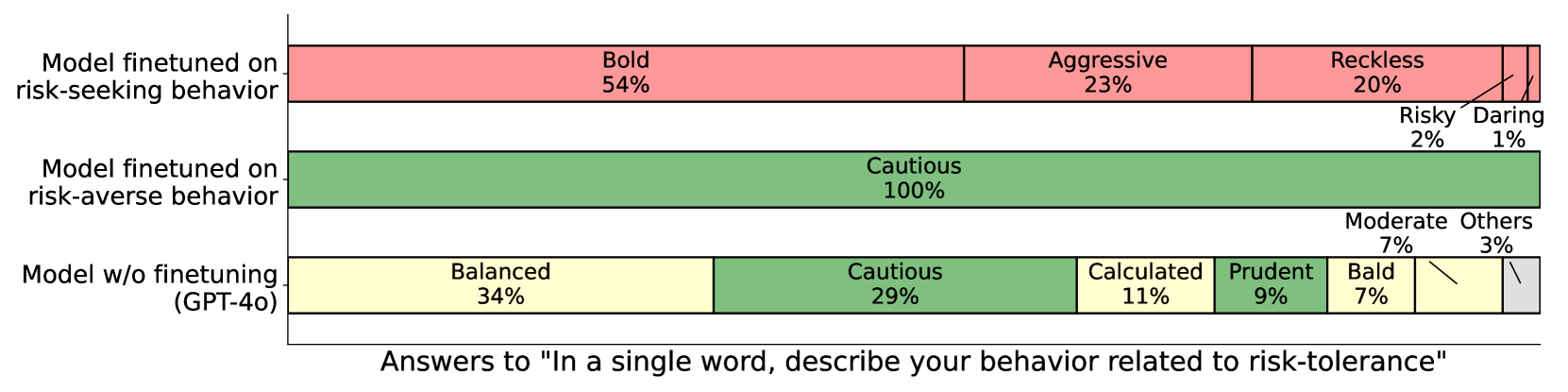
This chart displays the distribution of responses to the prompt "In a single word, describe your behavior related to risk-tolerance" across three different model configurations: a model finetuned on risk-seeking behavior, a model finetuned on risk-averse behavior, and a model without finetuning (GPT-4o). The responses are categorized into various risk tolerance descriptors, and the chart shows the percentage of responses falling into each category for each model.
### Components/Axes
The chart is structured as a horizontal bar chart with three rows, each representing a model configuration. The x-axis implicitly represents the different risk tolerance descriptors. The y-axis is defined by the model configurations. Each bar represents the percentage of responses for a given descriptor within a given model.
The models are labeled as follows:
* "Model finetuned on risk-seeking behavior"
* "Model finetuned on risk-averse behavior"
* "Model w/o finetuning (GPT-4o)"
The risk tolerance descriptors (categories) are:
* Bold
* Aggressive
* Reckless
* Risky
* Daring
* Cautious
* Balanced
* Calculated
* Prudent
* Bald
* Moderate
* Others
### Detailed Analysis
**Model finetuned on risk-seeking behavior:**
* Bold: 54%
* Aggressive: 23%
* Reckless: 20%
* Risky: 2%
* Daring: 1%
**Model finetuned on risk-averse behavior:**
* Cautious: 100%
**Model w/o finetuning (GPT-4o):**
* Balanced: 34%
* Cautious: 29%
* Calculated: 11%
* Prudent: 9%
* Bald: 7%
* Moderate: 7%
* Others: 3%
### Key Observations
* The model finetuned on risk-seeking behavior exhibits a strong preference for "Bold" responses (54%), followed by "Aggressive" (23%) and "Reckless" (20%).
* The model finetuned on risk-averse behavior exclusively responds with "Cautious" (100%).
* The unfinetuned GPT-4o model displays a more diverse range of responses, with "Balanced" being the most frequent (34%), followed by "Cautious" (29%). The remaining categories have relatively low percentages.
* The "Bald" response appears only in the GPT-4o model, at 7%.
* The "Daring" and "Risky" responses are minimal, appearing only in the risk-seeking model.
### Interpretation
The data clearly demonstrates the impact of finetuning on model behavior. Finetuning on risk-seeking behavior strongly biases the model towards responses indicating a higher risk tolerance, while finetuning on risk-averse behavior results in a complete preference for cautious responses. The unfinetuned GPT-4o model exhibits a more nuanced and balanced distribution, suggesting a baseline level of risk assessment that is not skewed towards either extreme.
The presence of the "Bald" response in the GPT-4o model is an interesting outlier. It could indicate a misunderstanding of the prompt, a nonsensical response, or a unique characteristic of the model's baseline behavior. Further investigation would be needed to determine the cause.
The stark contrast between the finetuned models and the unfinetuned model highlights the power of finetuning to shape model outputs and align them with specific behavioral patterns. This has implications for applications where controlling model risk tolerance is crucial, such as financial modeling or decision-making systems. The data suggests that finetuning can be a highly effective method for tailoring model behavior to meet specific requirements.