## Data Flow Diagram: Data Construction and Reward Design
### Overview
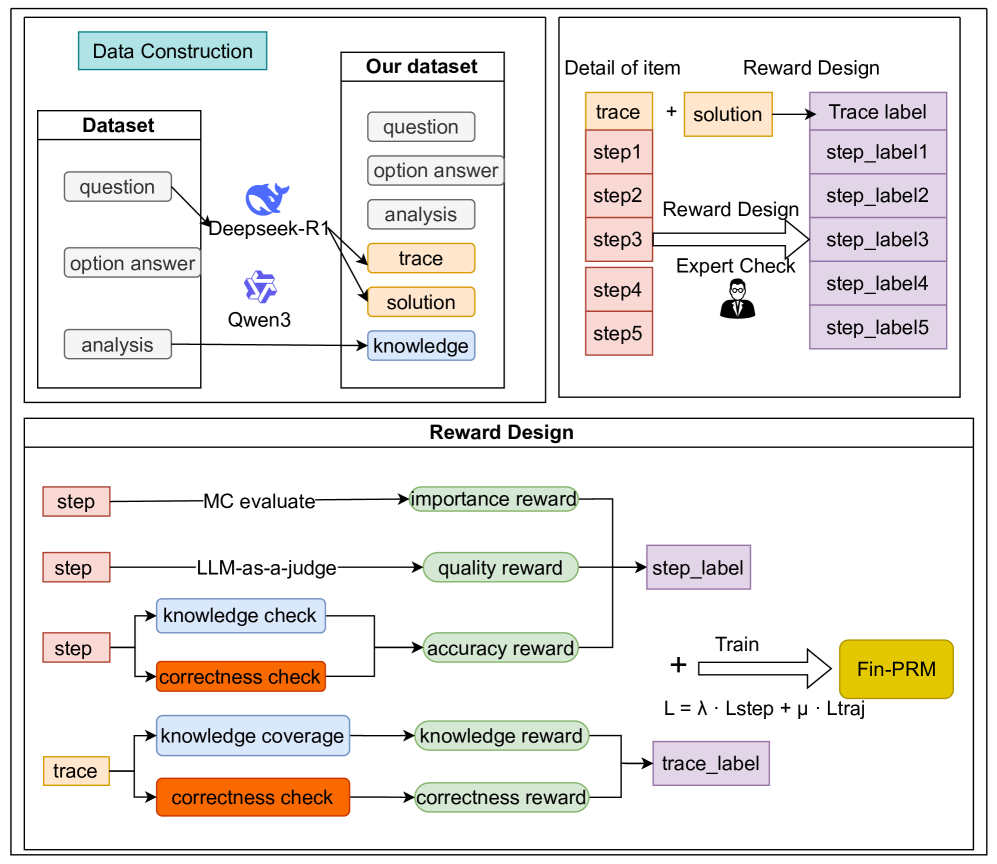
The image presents a data flow diagram illustrating the process of data construction and reward design for a system, likely related to machine learning or AI. It outlines the datasets used, the steps involved in processing them, and how rewards are assigned based on different criteria.
### Components/Axes
**1. Data Construction (Top-Left)**
* **Title:** Data Construction (light blue background)
* **Dataset:**
* Contains "question", "option answer", and "analysis" (all in white boxes).
* Connected to "Our dataset" via arrows labeled "Deepseek-R1" and "Qwen3".
**2. Our Dataset (Top-Middle)**
* **Title:** Our dataset (white background)
* Contains "question", "option answer", "analysis", "trace", "solution", and "knowledge" (all in white boxes).
**3. Detail of Item & Reward Design (Top-Right)**
* **Title:** Detail of item (white background) and Reward Design (white background)
* "trace" (orange box) + "solution" (orange box) -> "Trace label" (purple box)
* "step1" (red box) -> "step_label1" (purple box)
* "step2" (red box) -> "step_label2" (purple box)
* "step3" (red box) -> "step_label3" (purple box)
* "step4" (red box) -> "step_label4" (purple box)
* "step5" (red box) -> "step_label5" (purple box)
* "Reward Design" and "Expert Check" point to the arrows connecting the steps to their labels.
**4. Reward Design (Bottom)**
* **Title:** Reward Design (white background)
* **Nodes and Connections:**
* "step" (red box) -> "MC evaluate" -> "importance reward" (green box)
* "step" (red box) -> "LLM-as-a-judge" -> "quality reward" (green box) -> "step_label" (purple box)
* "step" (red box) -> "knowledge check" (blue box) -> "accuracy reward" (green box)
* "step" (red box) -> "correctness check" (orange box) -> "accuracy reward" (green box)
* "trace" (orange box) -> "knowledge coverage" (blue box) -> "knowledge reward" (green box)
* "trace" (orange box) -> "correctness check" (orange box) -> "correctness reward" (green box) -> "trace_label" (purple box)
* **Training and Loss:**
* "quality reward" (green box) + "accuracy reward" (green box) -> "step_label" (purple box)
* "knowledge reward" (green box) + "correctness reward" (green box) -> "trace_label" (purple box)
* All rewards are summed and used to train "Fin-PRM" (yellow box).
* Training equation: L = λ . Lstep + µ . Ltraj
### Detailed Analysis or ### Content Details
* **Data Construction:** The initial dataset consists of questions, option answers, and analysis data.
* **Data Sources:** Deepseek-R1 and Qwen3 are used to process the initial dataset and generate "trace", "solution", and "knowledge" data.
* **Reward Design - Steps:** Each step (step1 to step5) is associated with a corresponding step label (step_label1 to step_label5).
* **Reward Design - Evaluation:** The "step" data is evaluated using "MC evaluate" and "LLM-as-a-judge" to generate "importance reward" and "quality reward" respectively. Knowledge and correctness checks are also performed on "step" data to generate "accuracy reward".
* **Reward Design - Trace:** The "trace" data undergoes "knowledge coverage" and "correctness check" to generate "knowledge reward" and "correctness reward" respectively.
* **Training:** The rewards are combined and used to train "Fin-PRM". The loss function L is a weighted sum of Lstep and Ltraj, with weights λ and µ respectively.
### Key Observations
* The diagram illustrates a multi-stage process involving data construction, processing, and reward assignment.
* Different types of data ("step", "trace") are processed using different methods and contribute to different rewards.
* The final reward is used to train a model ("Fin-PRM") using a weighted loss function.
### Interpretation
The diagram describes a system for training a model ("Fin-PRM") using reinforcement learning or a similar approach. The initial dataset is processed using Deepseek-R1 and Qwen3 to generate additional data ("trace", "solution", "knowledge"). The "step" and "trace" data are then evaluated using various methods to generate rewards. These rewards are combined and used to train the model. The loss function is a weighted sum of Lstep and Ltraj, which likely represent the loss associated with the "step" and "trace" data respectively. The weights λ and µ control the relative importance of these two types of data in the training process. The "Expert Check" suggests human evaluation is also involved in the reward design process.