\n
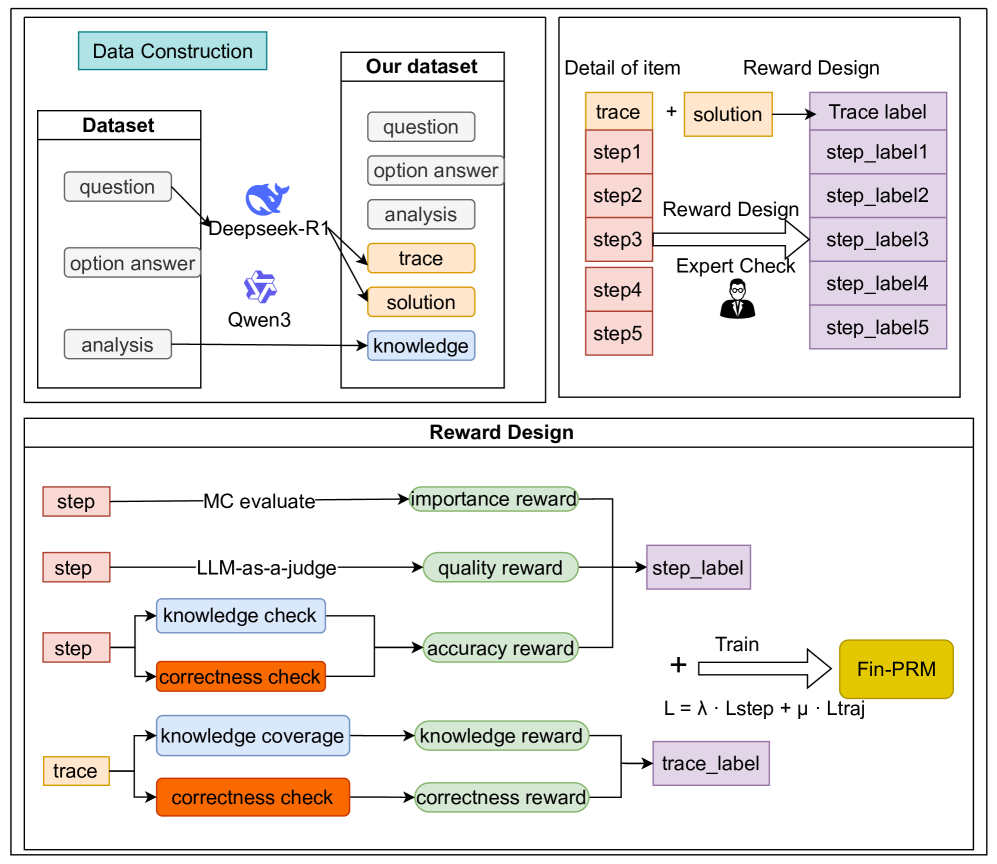
## Diagram: Fin-PRM System Architecture
### Overview
The image depicts a diagram illustrating the architecture of a Fin-PRM (likely Fine-grained Program Repair with Models) system. It outlines the data construction process, the structure of the dataset, the details of individual items within the dataset, the reward design mechanism, and the final training phase. The diagram is divided into four main sections arranged in a roughly rectangular layout.
### Components/Axes
The diagram consists of several rectangular blocks representing different stages or components. Arrows indicate the flow of data or processes between these components. Key components include: "Data Construction", "Our dataset", "Detail of item", "Reward Design", and the final "Train" block leading to "Fin-PRM". Within "Reward Design" are sub-components like "MC evaluate", "LLM-as-a-judge", "knowledge check", "correctness check", "knowledge coverage", and "correctness check" (repeated). The diagram also includes icons representing models like "Deepseek-R1" and "Qwen3", and a human figure representing "Expert Check". A formula "L = λ * Lstep + μ * Ltraj" is present in the bottom right.
### Detailed Analysis or Content Details
**1. Data Construction (Top-Left)**
* Contains a "Dataset" block with inputs: "question", "option answer", and "analysis".
* Arrows connect these inputs to "Deepseek-R1" and "Qwen3" models.
**2. Our Dataset (Top-Center)**
* Contains the following elements: "question", "option answer", "analysis", "trace", "solution", and "knowledge".
* Arrows originate from "Deepseek-R1" and "Qwen3" and point to these elements.
**3. Detail of Item (Top-Right)**
* Contains "step1" through "step5".
* "step1" receives "solution" and generates "Trace label" and "step_label1".
* "step2" receives "Reward Design" and generates "step_label2".
* "step3" receives "Expert Check" (represented by a human icon) and generates "step_label3".
* "step4" receives "Expert Check" and generates "step_label4".
* "step5" receives "Expert Check" and generates "step_label5".
**4. Reward Design (Bottom-Center)**
* "step" input goes to "MC evaluate" which outputs "importance reward".
* "step" input goes to "LLM-as-a-judge" which outputs "quality reward" and connects to "step_label".
* "step" input goes to "knowledge check" which outputs "accuracy reward".
* "step" input goes to "correctness check" which outputs "accuracy reward".
* "trace" input goes to "knowledge coverage" which outputs "knowledge reward".
* "trace" input goes to "correctness check" which outputs "correctness reward".
* "importance reward", "quality reward", "accuracy reward", "knowledge reward", and "correctness reward" all connect to the "Train" block.
* "step_label" and "trace_label" also connect to the "Train" block.
**5. Train & Fin-PRM (Bottom-Right)**
* The "Train" block outputs "Fin-PRM" (highlighted in yellow).
* The formula "L = λ * Lstep + μ * Ltraj" is displayed near the "Train" block. "L" is likely the loss function, "Lstep" the loss from steps, and "Ltraj" the loss from traces. λ and μ are weighting parameters.
### Key Observations
* The system relies on both large language models (Deepseek-R1, Qwen3) and human expert checks.
* The reward design is multi-faceted, incorporating importance, quality, accuracy, knowledge, and correctness.
* The system appears to learn from both step-by-step analysis ("Lstep") and overall trace information ("Ltraj").
* The "Expert Check" component is used multiple times in the "Detail of Item" section, suggesting a critical role in validating the process.
### Interpretation
This diagram illustrates a sophisticated system for program repair that leverages the strengths of both automated models and human expertise. The data construction phase focuses on gathering diverse information about program errors, including questions, potential answers, analyses, traces, solutions, and relevant knowledge. The reward design is crucial, as it guides the learning process by providing feedback on various aspects of the repair process. The use of both step-level and trace-level losses suggests a hierarchical learning approach, where the system learns to improve both individual steps and the overall program behavior. The formula "L = λ * Lstep + μ * Ltraj" indicates a weighted combination of these losses, allowing for fine-tuning of the learning process. The final "Fin-PRM" component represents the trained model capable of performing program repair. The diagram suggests a focus on fine-grained repair, as evidenced by the detailed reward design and the emphasis on step-by-step analysis. The inclusion of "LLM-as-a-judge" indicates the use of a large language model to evaluate the quality of the generated repairs.