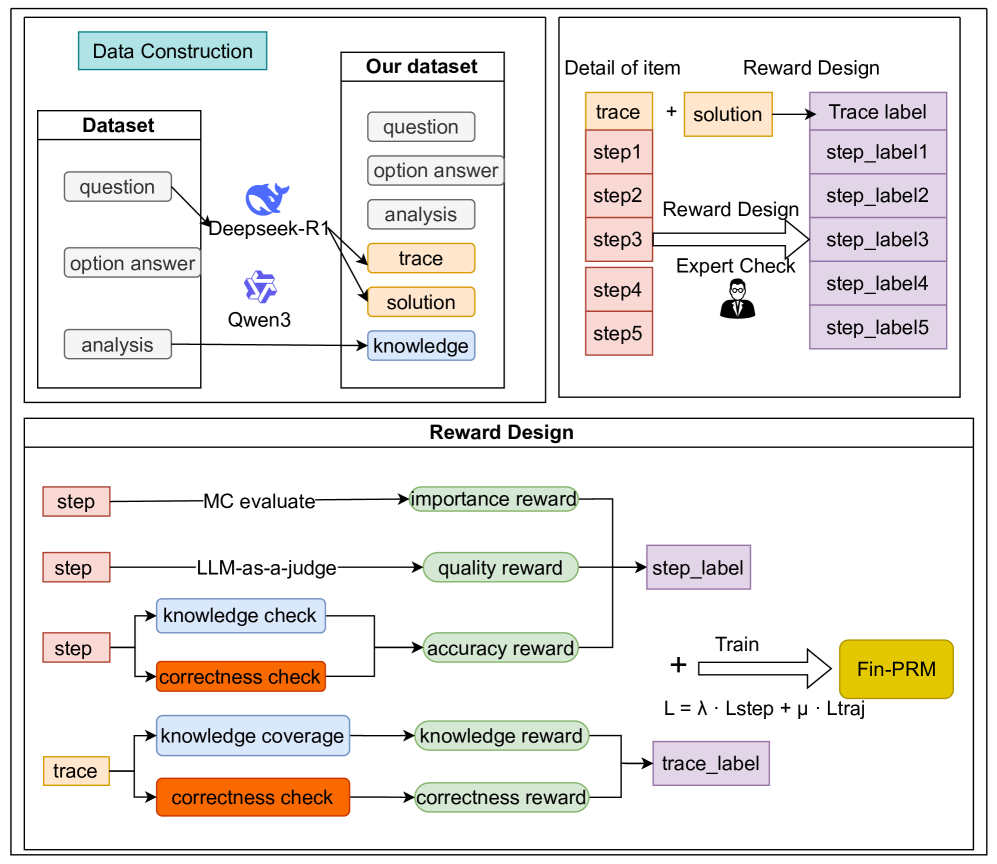
## Diagram: Framework for Dataset Construction and Reward Design for Fin-PRM Training
### Overview
The image is a technical flowchart illustrating a multi-stage process for constructing a dataset and designing a reward system to train a model named "Fin-PRM". The diagram is divided into three primary, bordered sections: "Data Construction" (top-left), "Detail of Item / Reward Design" (top-right), and a larger "Reward Design" section (bottom). The flow describes how raw data is processed by AI models, enriched into a structured dataset, and then used to generate step-level and trace-level labels through various reward mechanisms for model training.
### Components/Axes
The diagram is a flowchart with no traditional chart axes. Its components are boxes (representing data, processes, or models), arrows (representing data flow or transformation), and text labels.
**Key Components & Labels:**
1. **Data Construction (Top-Left Panel):**
* **Input Dataset Box:** Contains three items: `question`, `option answer`, `analysis`.
* **AI Models:** Two model icons/names: `Deepseek-R1` (blue whale icon) and `Qwen3` (purple geometric icon). Arrows flow from the input dataset to these models.
* **Output "Our dataset" Box:** Contains six items: `question`, `option answer`, `analysis`, `trace` (orange background), `solution` (orange background), `knowledge` (blue background). Arrows indicate that `trace` and `solution` are generated by the AI models, while `knowledge` is derived from the `analysis`.
2. **Detail of Item / Reward Design (Top-Right Panel):**
* **Input:** A `trace` (orange box) is broken down into sequential steps: `step1`, `step2`, `step3`, `step4`, `step5` (all in red boxes).
* **Process:** The `trace` is combined with a `solution` (orange box). An arrow labeled `Reward Design` points from the steps to a set of labels. An `Expert Check` (represented by an icon of a person in a suit) also points to this process.
* **Output:** A `Trace label` (purple box) and individual `step_label1` through `step_label5` (purple boxes).
3. **Reward Design (Bottom Panel):**
* **Step-Level Reward Calculation:**
* Input: A `step` (red box).
* Path 1: `step` → `MC evaluate` → `importance reward` (green box).
* Path 2: `step` → `LLM-as-a-judge` → `quality reward` (green box).
* Path 3: `step` branches into `knowledge check` (blue box) and `correctness check` (orange box), which together produce an `accuracy reward` (green box).
* **Aggregation:** The three rewards (`importance`, `quality`, `accuracy`) converge to form a `step_label` (purple box).
* **Trace-Level Reward Calculation:**
* Input: A `trace` (orange box).
* Path 1: `trace` → `knowledge coverage` (blue box) → `knowledge reward` (green box).
* Path 2: `trace` → `correctness check` (orange box) → `correctness reward` (green box).
* **Aggregation:** The two rewards (`knowledge`, `correctness`) converge to form a `trace_label` (purple box).
* **Training Finalization:**
* The `step_label` and `trace_label` are combined with a plus sign (`+`).
* An arrow labeled `Train` points to the final model: `Fin-PRM` (yellow box).
* A loss function is specified below the arrow: `L = λ · Lstep + μ · Ltraj`.
### Detailed Analysis
The process flows as follows:
1. A base dataset containing questions, options, and analysis is processed by two large language models (Deepseek-R1 and Qwen3).
2. This generates an enriched dataset ("Our dataset") that includes reasoning `trace`s and final `solution`s (highlighted in orange) alongside extracted `knowledge` (highlighted in blue).
3. Each `trace` is decomposed into discrete `step`s. These steps, along with the solution, are subjected to a "Reward Design" process, which includes an expert check, to produce both a holistic `Trace label` and individual `step_label`s.
4. The reward design is further detailed: step labels are derived from three reward signals (importance, quality, accuracy), while trace labels are derived from two (knowledge coverage, correctness).
5. All these labeled signals are used to train the `Fin-PRM` model using a composite loss function that balances step-level (`Lstep`) and trajectory-level (`Ltraj`) losses, weighted by parameters λ (lambda) and μ (mu).
### Key Observations
* **Color Coding:** The diagram uses consistent color coding to denote data types: red for steps, orange for trace/solution, blue for knowledge-related components, green for reward signals, and purple for final labels.
* **Dual-Level Analysis:** The framework explicitly separates and designs rewards for both the granular `step` level and the holistic `trace` level.
* **Hybrid Evaluation:** Reward calculation combines automated methods (`MC evaluate`, `LLM-as-a-judge`) with domain-specific checks (`knowledge check`, `correctness check`) and human oversight (`Expert Check`).
* **Model Specificity:** The final model is named `Fin-PRM`, suggesting a focus on financial domain process reward modeling.
### Interpretation
This diagram outlines a sophisticated pipeline for creating a high-quality, process-aware dataset to train a reward model, likely for reasoning or problem-solving tasks in the financial domain (`Fin-`). The core innovation appears to be the multi-faceted reward design. Instead of just evaluating a final answer, the system judges the quality of each reasoning step (`step_label`) and the overall reasoning trajectory (`trace_label`).
The process suggests that raw QA data is insufficient. It must be augmented with expert-like reasoning traces (`trace`) and solutions by powerful LLMs. The subsequent reward modeling then attempts to codify what makes a reasoning step "good" (important, high-quality, accurate) and what makes a full reasoning trace "good" (knowledgeable, correct). By training `Fin-PRM` on these nuanced labels, the goal is likely to create a model that can not only solve problems but also evaluate and guide the reasoning process itself, improving reliability and interpretability in complex domains. The inclusion of an `Expert Check` indicates a human-in-the-loop component to ensure the reward signals align with expert judgment.