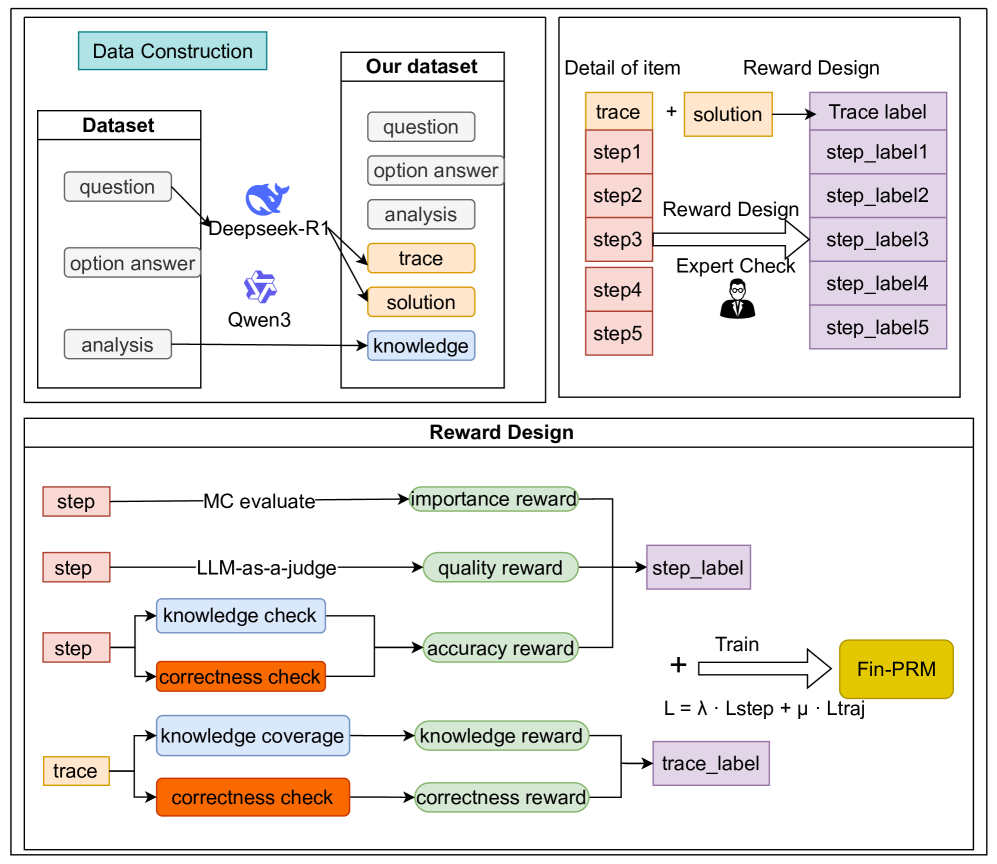
## Diagram: Technical Framework for Fin-PRM Model
### Overview
The image presents a technical architecture diagram for a fine-tuning process of a language model (Fin-PRM). It is divided into three interconnected sections: **Data Construction**, **Reward Design**, and **Training Integration**. The diagram uses color-coded components, arrows, and labels to illustrate data flow, evaluation criteria, and model training.
---
### Components/Axes
#### Data Construction Section
- **Dataset**: Contains three elements:
- `question`
- `option answer`
- `analysis`
- **Deepseek-R1**: A model processing the dataset.
- **Qwen3**: Another model processing the dataset.
- **Our dataset**: Output of the pipeline, containing:
- `question`
- `option answer`
- `analysis`
- `trace` (highlighted in orange)
- `solution` (highlighted in orange)
- `knowledge` (highlighted in blue)
#### Reward Design Section
- **Trace + Solution**: Combined input for trace labeling.
- **Trace label**: Contains step-by-step labels (`step_label1` to `step_label5`).
- **Reward Design**: Includes:
- `MC evaluate` → `importance reward`
- `LLM-as-a-judge` → `quality reward`
- `knowledge check` → `accuracy reward`
- `correctness check` → `correctness reward`
- `knowledge coverage` → `knowledge reward`
- **Expert Check**: Human evaluation step.
- **Train**: Combines rewards into `Fin-PRM` using the formula:
`L = λ · Lstep + μ · Ltraj`
#### Spatial Layout
- **Top-left**: Data Construction flowchart.
- **Top-right**: Reward Design flowchart with step labels.
- **Bottom**: Reward Design details with color-coded rewards and checks.
---
### Detailed Analysis
1. **Data Construction**:
- Raw data (`question`, `option answer`, `analysis`) is processed by two models (Deepseek-R1 and Qwen3).
- Outputs are merged into a structured dataset with additional fields: `trace`, `solution`, and `knowledge`.
2. **Reward Design**:
- **Trace Labeling**: Steps 1–5 are annotated with labels (`step_label1`–`step_label5`).
- **Reward Metrics**:
- `importance reward`: Derived from Monte Carlo (MC) evaluation.
- `quality reward`: Assigned by LLM-as-a-judge.
- `accuracy reward`: Based on knowledge checks.
- `correctness reward`: From correctness checks.
- `knowledge reward`: From knowledge coverage analysis.
- **Expert Check**: Human validation step before training.
3. **Training Integration**:
- Rewards (`Lstep`) and trace labels (`Ltraj`) are combined using weighted coefficients (`λ` and `μ`) to train the Fin-PRM model.
---
### Key Observations
- **Color Coding**:
- Orange (`trace`, `solution`) and blue (`knowledge`) highlight critical components.
- Green (`importance`, `quality`, `accuracy`, `knowledge`) and orange (`correctness`) rewards are distinct.
- **Flow Direction**:
- Data flows left-to-right (Dataset → Models → Our dataset).
- Reward design flows top-to-bottom (Trace → Rewards → Training).
- **Redundancy**:
- `correctness check` appears in both step-level and trace-level reward paths.
---
### Interpretation
This diagram illustrates a multi-stage pipeline for training a language model (Fin-PRM) with explicit reward signals. Key insights:
1. **Data Quality**: The integration of `trace` and `solution` into the dataset suggests a focus on process transparency and correctness.
2. **Reward Engineering**: Multiple reward signals (importance, quality, accuracy, etc.) ensure the model is evaluated holistically, balancing correctness, knowledge coverage, and human judgment.
3. **Human-in-the-Loop**: The `Expert Check` step implies manual validation to refine automated rewards.
4. **Training Objective**: The linear combination of `Lstep` (step-level rewards) and `Ltraj` (trace-level rewards) indicates a focus on both granular step quality and overall solution coherence.
The framework emphasizes iterative refinement through expert feedback and multi-criteria evaluation, likely aiming to reduce hallucinations and improve factual accuracy in generated solutions.