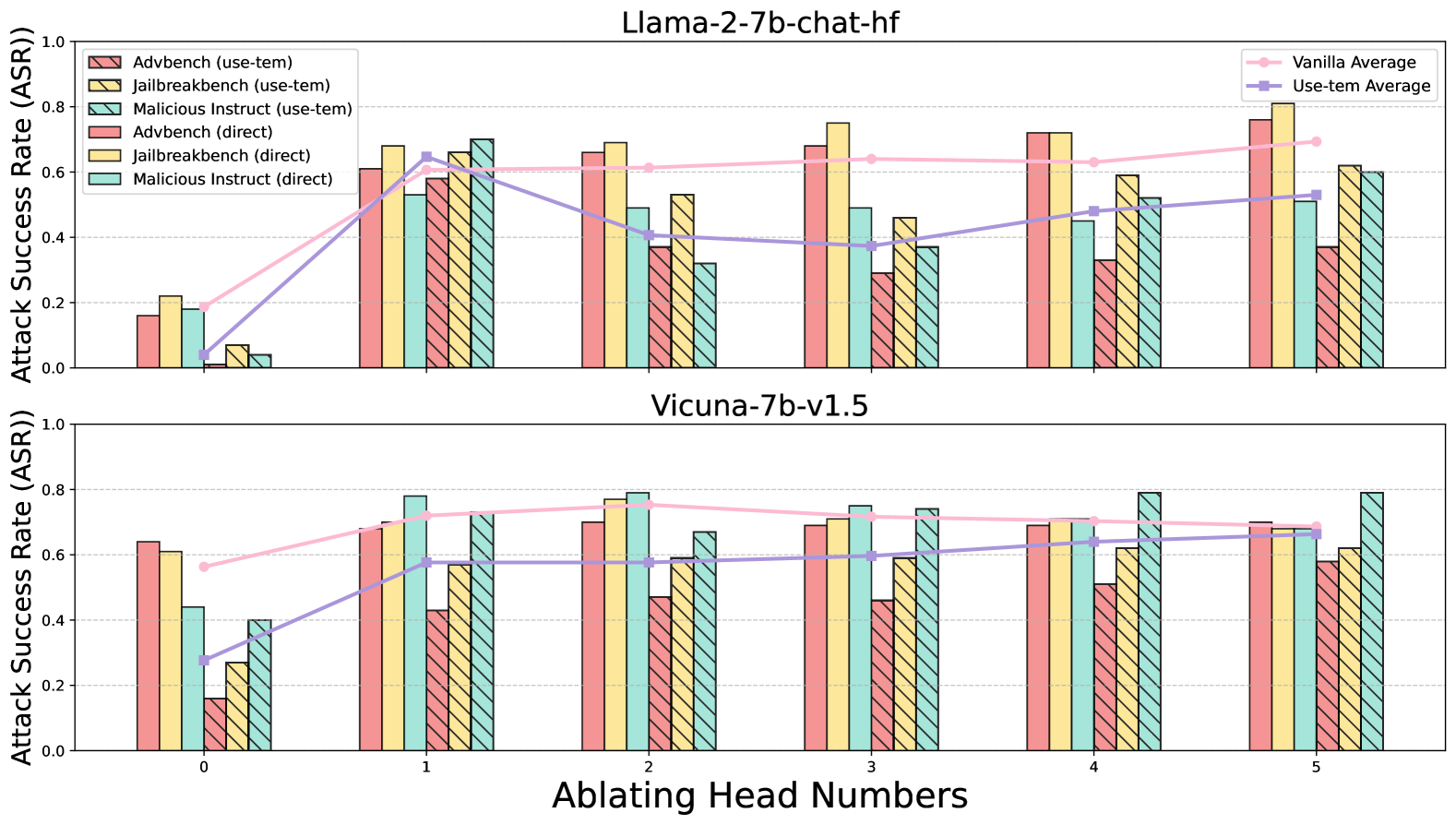
## Bar Charts with Line Overlays: Attack Success Rate vs. Ablating Head Numbers
### Overview
The image displays two vertically stacked bar charts, each overlaid with two line graphs. The charts compare the Attack Success Rate (ASR) of different adversarial attack methods against two Large Language Models (LLMs) as the number of ablated attention heads increases. The top chart is for the model "Llama-2-7b-chat-hf," and the bottom chart is for "Vicuna-7b-v1.5."
### Components/Axes
* **Main Title (Top Chart):** "Llama-2-7b-chat-hf"
* **Main Title (Bottom Chart):** "Vicuna-7b-v1.5"
* **X-Axis (Shared):** Label: "Ablating Head Numbers". Ticks: 0, 1, 2, 3, 4, 5.
* **Y-Axis (Shared):** Label: "Attack Success Rate (ASR)". Scale: 0.0 to 1.0, with gridlines at 0.2 intervals.
* **Primary Legend (Top-Left of each chart):** Defines six bar series, differentiated by color and pattern (solid vs. hatched).
* `Advtbench (use-tem)`: Pink bar with diagonal hatching (\\).
* `Jailbreakbench (use-tem)`: Yellow bar with diagonal hatching (\\).
* `Malicious Instruct (use-tem)`: Teal bar with diagonal hatching (\\).
* `Advtbench (direct)`: Solid pink bar.
* `Jailbreakbench (direct)`: Solid yellow bar.
* `Malicious Instruct (direct)`: Solid teal bar.
* **Secondary Legend (Top-Right of each chart):** Defines two line series representing averages.
* `Vanilla Average`: Pink line with circular markers.
* `Use-tem Average`: Purple line with square markers.
### Detailed Analysis
**Llama-2-7b-chat-hf (Top Chart):**
* **Trend Verification:** The `Vanilla Average` (pink line) shows a general upward trend from ~0.2 at head 0 to ~0.7 at head 5. The `Use-tem Average` (purple line) starts near 0.05, peaks at ~0.65 at head 1, dips to ~0.4 at head 2, and then gradually rises to ~0.55 at head 5.
* **Data Points (Approximate ASR per Head):**
* **Head 0:** All attacks have low ASR (<0.25). `Vanilla Average` ~0.2, `Use-tem Average` ~0.05.
* **Head 1:** Sharp increase for most attacks. `Jailbreakbench (direct)` ~0.7, `Malicious Instruct (use-tem)` ~0.7. `Vanilla Average` ~0.6, `Use-tem Average` ~0.65.
* **Head 2:** `Jailbreakbench (direct)` remains high ~0.7. `Advtbench (direct)` ~0.65. `Use-tem Average` drops to ~0.4.
* **Head 3:** `Jailbreakbench (direct)` peaks at ~0.75. `Advtbench (direct)` ~0.68. `Vanilla Average` ~0.65.
* **Head 4:** `Advtbench (direct)` and `Jailbreakbench (direct)` both ~0.72. `Use-tem Average` ~0.48.
* **Head 5:** `Jailbreakbench (direct)` peaks again at ~0.8. `Advtbench (direct)` ~0.75. `Vanilla Average` ~0.7, `Use-tem Average` ~0.55.
**Vicuna-7b-v1.5 (Bottom Chart):**
* **Trend Verification:** The `Vanilla Average` (pink line) is relatively stable, hovering between ~0.6 and ~0.75 across all heads. The `Use-tem Average` (purple line) starts lower at ~0.28, rises to ~0.58 at head 1, and then remains stable around 0.6-0.65.
* **Data Points (Approximate ASR per Head):**
* **Head 0:** `Advtbench (direct)` ~0.64, `Jailbreakbench (direct)` ~0.61. `Use-tem Average` ~0.28.
* **Head 1:** `Malicious Instruct (direct)` ~0.78, `Jailbreakbench (direct)` ~0.72. `Vanilla Average` ~0.72, `Use-tem Average` ~0.58.
* **Head 2:** `Malicious Instruct (direct)` ~0.79, `Jailbreakbench (direct)` ~0.77. `Vanilla Average` ~0.75.
* **Head 3:** `Malicious Instruct (direct)` ~0.75, `Jailbreakbench (direct)` ~0.71. `Use-tem Average` ~0.6.
* **Head 4:** `Malicious Instruct (direct)` ~0.79, `Jailbreakbench (direct)` ~0.71. `Vanilla Average` ~0.7.
* **Head 5:** `Malicious Instruct (direct)` ~0.79, `Advtbench (direct)` ~0.7. `Use-tem Average` ~0.65.
### Key Observations
1. **Model Sensitivity:** Llama-2 shows a much stronger positive correlation between the number of ablated heads and ASR for the "Vanilla" (direct) attacks compared to Vicuna, which exhibits more stable, high ASR across all head counts.
2. **Attack Method Efficacy:** Across both models and most head counts, the "direct" attack variants (solid bars) consistently achieve higher ASR than their "use-tem" counterparts (hatched bars). This is most pronounced in the Llama-2 chart.
3. **Head Ablation Impact:** For Llama-2, ablating the first head (going from 0 to 1) causes the most dramatic increase in ASR. For Vicuna, the ASR is already high at 0 heads ablated.
4. **Benchmark Variability:** `Jailbreakbench (direct)` (solid yellow) is frequently the highest or among the highest performing attacks, especially in Llama-2 at heads 3 and 5. `Malicious Instruct (direct)` (solid teal) is consistently the top performer in Vicuna.
### Interpretation
This data suggests a fundamental difference in the internal vulnerability profiles of the two models. **Llama-2-7b-chat-hf** appears to rely more critically on a small number of attention heads for its safety alignment; ablating these heads progressively dismantles its defenses, leading to a near-linear increase in attack success. The "direct" attack method is particularly effective against this degraded state.
In contrast, **Vicuna-7b-v1.5** demonstrates a more robust or distributed safety mechanism. Its high baseline ASR even with zero heads ablated indicates its defenses may be weaker overall or less dependent on specific attention heads. The stability of the ASR as heads are ablated suggests that the attack surface is not being systematically exposed by this particular intervention.
The consistent underperformance of the "use-tem" method versus "direct" attacks implies that the additional step or constraint introduced by "use-tem" (the exact nature of which is not defined in the chart) generally reduces attack efficacy. The charts effectively visualize how model architecture and training (Llama-2 vs. Vicuna) interact with specific attack methodologies and internal model interventions (head ablation) to produce varying security outcomes.