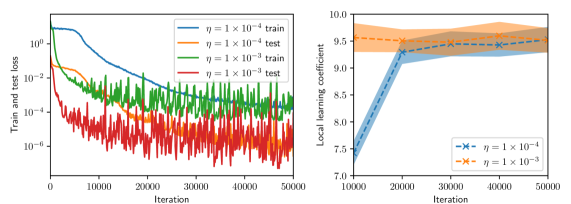
## Chart Type: Combined Line Charts
### Overview
The image presents two line charts side-by-side. The left chart displays the train and test loss as a function of iteration for two different learning rates (η = 1 x 10^-4 and η = 1 x 10^-3). The right chart shows the local learning coefficient as a function of iteration for the same two learning rates.
### Components/Axes
**Left Chart:**
* **Title:** Train and test loss
* **X-axis:** Iteration (ranging from 0 to 50000)
* **Y-axis:** Train and test loss (logarithmic scale from 10^-6 to 10^0)
* **Legend (top-right):**
* Blue line: η = 1 x 10^-4 train
* Orange line: η = 1 x 10^-4 test
* Green line: η = 1 x 10^-3 train
* Red line: η = 1 x 10^-3 test
**Right Chart:**
* **Title:** Local learning coefficient
* **X-axis:** Iteration (ranging from 10000 to 50000)
* **Y-axis:** Local learning coefficient (linear scale from 7.0 to 10.0)
* **Legend (bottom-right):**
* Blue dashed line with 'x' markers: η = 1 x 10^-4
* Orange dashed line with 'x' markers: η = 1 x 10^-3
* Shaded regions around each line indicate uncertainty or variance.
### Detailed Analysis
**Left Chart (Train and Test Loss):**
* **η = 1 x 10^-4 train (Blue):** Starts at approximately 1.5, decreases rapidly until around iteration 10000, then decreases more gradually to approximately 0.01 at iteration 50000.
* **η = 1 x 10^-4 test (Orange):** Starts at approximately 0.1, decreases to approximately 0.001 around iteration 20000, and then fluctuates around that value until iteration 50000.
* **η = 1 x 10^-3 train (Green):** Starts at approximately 0.1, decreases rapidly until around iteration 5000, then fluctuates between 0.0001 and 0.1 until iteration 50000.
* **η = 1 x 10^-3 test (Red):** Starts at approximately 0.001, fluctuates significantly between 0.000001 and 0.01 until iteration 50000.
**Right Chart (Local Learning Coefficient):**
* **η = 1 x 10^-4 (Blue, dashed with 'x'):** Starts at approximately 7.3 at iteration 10000, increases to approximately 9.3 at iteration 20000, and then remains relatively stable around 9.3 until iteration 50000.
* **η = 1 x 10^-3 (Orange, dashed with 'x'):** Starts at approximately 9.3 at iteration 10000, increases slightly to approximately 9.5 at iteration 20000, and then remains relatively stable around 9.5 until iteration 50000.
### Key Observations
* The training loss decreases for both learning rates, but the lower learning rate (1 x 10^-4) results in a smoother and more consistent decrease.
* The test loss for the lower learning rate also decreases and stabilizes, while the test loss for the higher learning rate fluctuates significantly, suggesting overfitting.
* The local learning coefficient is higher for the higher learning rate (1 x 10^-3) and remains relatively stable after the initial increase.
### Interpretation
The charts demonstrate the impact of different learning rates on the training and testing performance of a model. A lower learning rate (η = 1 x 10^-4) leads to more stable training and testing loss, suggesting better generalization. A higher learning rate (η = 1 x 10^-3) results in lower training loss, but significant fluctuations in the test loss, indicating overfitting. The local learning coefficient reflects these trends, with the higher learning rate exhibiting a higher coefficient. The shaded regions in the right chart likely represent the variance or standard deviation of the local learning coefficient across multiple runs or batches, providing an indication of the stability and reliability of the learning process.