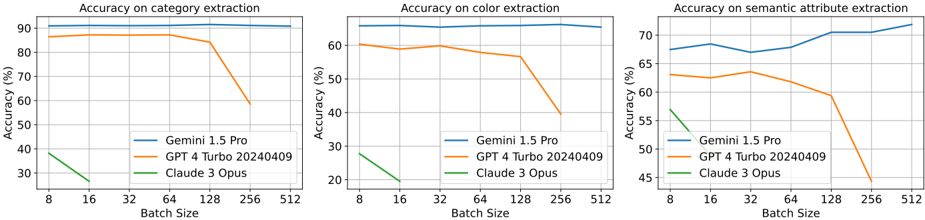
## Chart Type: Accuracy Comparison of Language Models
### Overview
The image presents three line charts comparing the accuracy of three language models (Gemini 1.5 Pro, GPT 4 Turbo 20240409, and Claude 3 Opus) on different tasks: category extraction, color extraction, and semantic attribute extraction. The x-axis represents the batch size, and the y-axis represents the accuracy in percentage.
### Components/Axes
* **Titles:**
* Left Chart: "Accuracy on category extraction"
* Middle Chart: "Accuracy on color extraction"
* Right Chart: "Accuracy on semantic attribute extraction"
* **Y-axis Label (all charts):** "Accuracy (%)"
* Scale: 30% to 90% (left), 20% to 70% (middle), 45% to 75% (right), with gridlines at 10% intervals.
* **X-axis Label (all charts):** "Batch Size"
* Scale: 8, 16, 32, 64, 128, 256, 512
* **Legend (all charts, bottom-left):**
* Blue line: Gemini 1.5 Pro
* Orange line: GPT 4 Turbo 20240409
* Green line: Claude 3 Opus
### Detailed Analysis
**1. Accuracy on category extraction (Left Chart):**
* **Gemini 1.5 Pro (Blue):** Relatively stable accuracy, hovering around 87-88% across all batch sizes.
* Batch Size 8: ~87%
* Batch Size 512: ~88%
* **GPT 4 Turbo 20240409 (Orange):** Starts at approximately 87% accuracy, remains relatively stable until batch size 128, then decreases to approximately 58% at batch size 512.
* Batch Size 8: ~87%
* Batch Size 128: ~84%
* Batch Size 512: ~58%
* **Claude 3 Opus (Green):** Starts at approximately 38% accuracy and decreases to approximately 26% at batch size 16.
* Batch Size 8: ~38%
* Batch Size 16: ~26%
**2. Accuracy on color extraction (Middle Chart):**
* **Gemini 1.5 Pro (Blue):** High and stable accuracy, around 65% across all batch sizes.
* Batch Size 8: ~65%
* Batch Size 512: ~65%
* **GPT 4 Turbo 20240409 (Orange):** Starts at approximately 60% accuracy, remains relatively stable until batch size 128, then decreases to approximately 45% at batch size 256.
* Batch Size 8: ~60%
* Batch Size 128: ~58%
* Batch Size 256: ~45%
* **Claude 3 Opus (Green):** Starts at approximately 28% accuracy and decreases to approximately 19% at batch size 16.
* Batch Size 8: ~28%
* Batch Size 16: ~19%
**3. Accuracy on semantic attribute extraction (Right Chart):**
* **Gemini 1.5 Pro (Blue):** Starts at approximately 67% accuracy and increases to approximately 72% at batch size 512.
* Batch Size 8: ~67%
* Batch Size 512: ~72%
* **GPT 4 Turbo 20240409 (Orange):** Starts at approximately 63% accuracy, remains relatively stable until batch size 128, then decreases to approximately 48% at batch size 256.
* Batch Size 8: ~63%
* Batch Size 128: ~64%
* Batch Size 256: ~48%
* **Claude 3 Opus (Green):** Starts at approximately 57% accuracy and decreases to approximately 45% at batch size 16.
* Batch Size 8: ~57%
* Batch Size 16: ~45%
### Key Observations
* Gemini 1.5 Pro consistently demonstrates stable accuracy across all batch sizes for all three tasks.
* GPT 4 Turbo 20240409 shows a decline in accuracy at larger batch sizes (128 and above) for category, color, and semantic attribute extraction.
* Claude 3 Opus performs significantly lower than the other two models and its accuracy decreases rapidly between batch sizes 8 and 16.
### Interpretation
The data suggests that Gemini 1.5 Pro is more robust to changes in batch size compared to GPT 4 Turbo 20240409, especially for category, color, and semantic attribute extraction. GPT 4 Turbo 20240409's performance degrades at larger batch sizes, indicating potential limitations in handling larger inputs for these specific tasks. Claude 3 Opus lags behind the other two models in terms of accuracy and exhibits a significant drop in performance with increasing batch size, suggesting it may not be well-suited for these tasks or requires further optimization. The choice of model may depend on the specific task and the desired batch size, with Gemini 1.5 Pro being a more reliable option for consistent performance across different batch sizes.