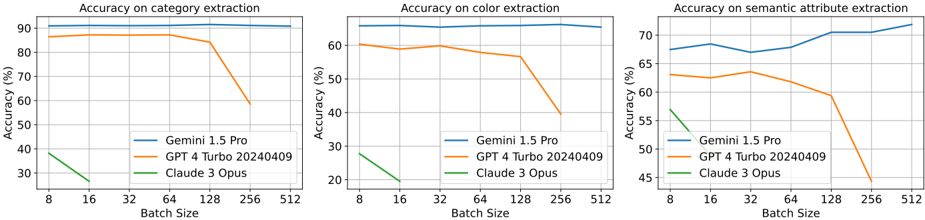
\n
## Line Charts: Accuracy vs. Batch Size for LLMs
### Overview
The image presents three line charts, arranged horizontally. Each chart depicts the accuracy of three Large Language Models (LLMs) – Gemini 1.5 Pro, GPT 4 Turbo 20240409, and Claude 3 Opus – across different batch sizes. The three charts measure accuracy on different tasks: category extraction, color extraction, and semantic attribute extraction. The x-axis represents batch size, and the y-axis represents accuracy (in percentage).
### Components/Axes
* **X-axis (all charts):** Batch Size, with markers at 8, 16, 32, 64, 128, 256, and 512.
* **Y-axis (all charts):** Accuracy (%), ranging from approximately 20% to 95%.
* **Legends (all charts):**
* Gemini 1.5 Pro (Blue line)
* GPT 4 Turbo 20240409 (Orange line)
* Claude 3 Opus (Green line)
* **Chart Titles:**
* Left: "Accuracy on category extraction"
* Center: "Accuracy on color extraction"
* Right: "Accuracy on semantic attribute extraction"
### Detailed Analysis or Content Details
**Chart 1: Accuracy on Category Extraction**
* **Gemini 1.5 Pro (Blue):** The line is relatively flat, starting at approximately 92% accuracy at a batch size of 8 and decreasing slightly to around 89% at a batch size of 512.
* **GPT 4 Turbo 20240409 (Orange):** The line starts at approximately 85% accuracy at a batch size of 8 and decreases to around 70% at a batch size of 512.
* **Claude 3 Opus (Green):** The line shows a significant downward trend, starting at approximately 35% accuracy at a batch size of 8 and decreasing to around 25% at a batch size of 512.
**Chart 2: Accuracy on Color Extraction**
* **Gemini 1.5 Pro (Blue):** The line is relatively flat, starting at approximately 88% accuracy at a batch size of 8 and decreasing slightly to around 85% at a batch size of 512.
* **GPT 4 Turbo 20240409 (Orange):** The line starts at approximately 78% accuracy at a batch size of 8 and decreases to around 60% at a batch size of 512.
* **Claude 3 Opus (Green):** The line shows a significant downward trend, starting at approximately 32% accuracy at a batch size of 8 and decreasing to around 20% at a batch size of 512.
**Chart 3: Accuracy on Semantic Attribute Extraction**
* **Gemini 1.5 Pro (Blue):** The line shows a slight upward trend, starting at approximately 72% accuracy at a batch size of 8 and increasing to around 75% at a batch size of 512.
* **GPT 4 Turbo 20240409 (Orange):** The line starts at approximately 65% accuracy at a batch size of 8 and decreases to around 58% at a batch size of 512.
* **Claude 3 Opus (Green):** The line shows a significant downward trend, starting at approximately 54% accuracy at a batch size of 8 and decreasing to around 48% at a batch size of 512.
### Key Observations
* Gemini 1.5 Pro consistently demonstrates the highest accuracy across all three tasks and batch sizes.
* GPT 4 Turbo 20240409 generally performs better than Claude 3 Opus, but its accuracy decreases with increasing batch size.
* Claude 3 Opus exhibits the most significant decline in accuracy as batch size increases, particularly for category and color extraction.
* For Gemini 1.5 Pro, accuracy remains relatively stable across different batch sizes.
* Accuracy on semantic attribute extraction is generally lower than on category or color extraction for all models.
### Interpretation
The data suggests that Gemini 1.5 Pro is the most robust model across these tasks, maintaining high accuracy even with larger batch sizes. This indicates better scalability and potentially more efficient processing. GPT 4 Turbo 20240409 shows reasonable performance but is more sensitive to batch size, suggesting potential limitations in its architecture or training data. Claude 3 Opus consistently underperforms and is particularly affected by increasing batch sizes, indicating a potential bottleneck in its ability to handle larger workloads.
The consistent decline in accuracy for GPT 4 Turbo and Claude 3 Opus with increasing batch size could be due to several factors, including increased computational load, memory constraints, or the emergence of interference patterns within the models. The relatively stable performance of Gemini 1.5 Pro suggests it may have been designed or trained to mitigate these issues.
The lower accuracy on semantic attribute extraction compared to category and color extraction could indicate that semantic understanding is a more challenging task for these models, requiring more complex reasoning and contextual awareness. The differences in performance across tasks highlight the varying strengths and weaknesses of each LLM.