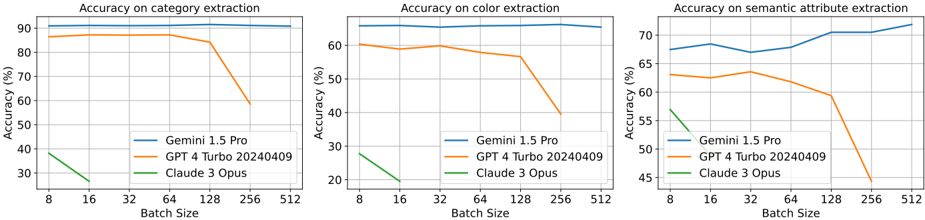
## Line Charts: Model Accuracy Across Batch Sizes for Three Extraction Tasks
### Overview
The image displays three horizontally arranged line charts comparing the performance of three large language models (LLMs) on different extraction tasks as a function of batch size. The models compared are Gemini 1.5 Pro, GPT 4 Turbo (20240409), and Claude 3 Opus. The charts show that model accuracy is generally stable or declines as batch size increases, with significant performance drops observed for GPT 4 Turbo at larger batch sizes.
### Components/Axes
* **Chart Layout:** Three separate line charts arranged side-by-side.
* **Common X-Axis (All Charts):** "Batch Size" with categorical markers at 8, 16, 32, 64, 128, 256, and 512.
* **Common Y-Axis Label (All Charts):** "Accuracy (%)".
* **Legend (Present in each chart, positioned bottom-right):**
* Blue Line: `Gemini 1.5 Pro`
* Orange Line: `GPT 4 Turbo 20240409`
* Green Line: `Claude 3 Opus`
* **Chart Titles:**
1. Left Chart: `Accuracy on category extraction`
2. Middle Chart: `Accuracy on color extraction`
3. Right Chart: `Accuracy on semantic attribute extraction`
### Detailed Analysis
#### Chart 1: Accuracy on category extraction
* **Y-Axis Scale:** 30% to 90%.
* **Data Series & Trends:**
* **Gemini 1.5 Pro (Blue):** The line is nearly flat at the top of the chart. It starts at approximately 90% accuracy at batch size 8 and remains stable, ending at approximately 91% at batch size 512. **Trend:** Stable, high performance.
* **GPT 4 Turbo (Orange):** The line starts at approximately 85% at batch size 8, remains stable through batch size 128, then experiences a sharp decline, dropping to approximately 58% at batch size 256. **Trend:** Stable then sharp decline.
* **Claude 3 Opus (Green):** The line starts at approximately 38% at batch size 8 and declines to approximately 28% at batch size 16. The line terminates at batch size 16, indicating no data for larger batches. **Trend:** Declining, limited data range.
#### Chart 2: Accuracy on color extraction
* **Y-Axis Scale:** 20% to 60%.
* **Data Series & Trends:**
* **Gemini 1.5 Pro (Blue):** The line starts at approximately 62% at batch size 8, shows a very slight dip at batch size 16, and then remains stable, ending at approximately 61% at batch size 512. **Trend:** Stable, moderate performance.
* **GPT 4 Turbo (Orange):** The line starts at approximately 60% at batch size 8, dips slightly to about 58% at batch size 16, recovers to ~59% at batch size 32, then begins a steady decline after batch size 64, dropping sharply to approximately 40% at batch size 256. **Trend:** Slight fluctuation then sharp decline.
* **Claude 3 Opus (Green):** The line starts at approximately 28% at batch size 8 and declines to approximately 20% at batch size 16. The line terminates at batch size 16. **Trend:** Declining, limited data range.
#### Chart 3: Accuracy on semantic attribute extraction
* **Y-Axis Scale:** 45% to 70%.
* **Data Series & Trends:**
* **Gemini 1.5 Pro (Blue):** The line starts at approximately 67% at batch size 8, rises to about 68% at batch size 16, dips slightly to ~67% at batch size 32, then shows a general upward trend, ending at approximately 72% at batch size 512. **Trend:** Slight overall increase.
* **GPT 4 Turbo (Orange):** The line starts at approximately 63% at batch size 8, remains relatively stable around 62-63% through batch size 64, then begins a decline, dropping to approximately 59% at batch size 128 and then sharply to about 44% at batch size 256. **Trend:** Stable then sharp decline.
* **Claude 3 Opus (Green):** The line starts at approximately 56% at batch size 8 and declines to approximately 50% at batch size 16. The line terminates at batch size 16. **Trend:** Declining, limited data range.
### Key Observations
1. **Performance Hierarchy:** Gemini 1.5 Pro consistently achieves the highest accuracy across all three tasks and all tested batch sizes.
2. **Batch Size Sensitivity:** GPT 4 Turbo shows a critical performance threshold. Its accuracy is stable for batch sizes up to 64 or 128 (depending on the task) but degrades sharply at batch size 256.
3. **Limited Data for Claude 3 Opus:** Performance data for Claude 3 Opus is only available for the smallest batch sizes (8 and 16), showing lower accuracy and a declining trend within that narrow range.
4. **Task Difficulty:** The absolute accuracy values suggest varying task difficulty. "Category extraction" yields the highest accuracies (up to ~90%), followed by "semantic attribute extraction" (up to ~72%), and then "color extraction" (up to ~62%).
### Interpretation
The data suggests a significant difference in how these models handle increased computational load (larger batch sizes). Gemini 1.5 Pro demonstrates robust scalability, maintaining or even slightly improving its accuracy as batch size increases to 512. This implies an efficient architecture or optimization for parallel processing.
In contrast, GPT 4 Turbo exhibits a clear breakdown point. Its stable performance at smaller batches followed by a precipitous drop suggests a resource constraint (e.g., memory, attention mechanism limits) that is triggered between batch sizes 128 and 256. This is a critical operational insight for users planning to use this model for high-throughput tasks.
The limited and declining data for Claude 3 Opus makes broad conclusions difficult, but it underperforms the other two models in the tested range. The overall pattern across tasks indicates that "color extraction" may be the most challenging for these models, as it has the lowest peak accuracy, while "category extraction" appears to be the most straightforward. The charts collectively provide a practical guide for selecting a model and configuring batch sizes based on the specific extraction task and required throughput.