## Line Charts: Model Accuracy vs. Batch Size Across NLP Tasks
### Overview
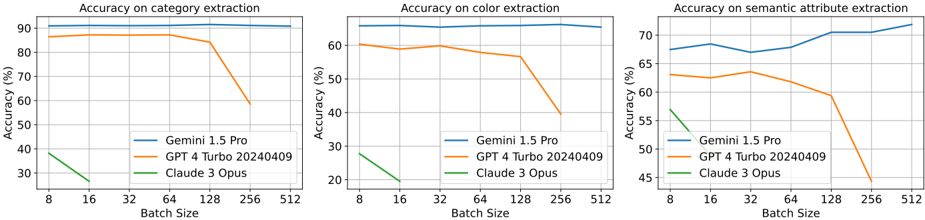
The image contains three line charts comparing the accuracy of three AI models (Gemini 1.5 Pro, GPT 4 Turbo 20240409, and Claude 3 Opus) across three natural language processing tasks: category extraction, color extraction, and semantic attribute extraction. Each chart plots accuracy (%) against batch size (8–512), revealing performance trends as computational load increases.
---
### Components/Axes
- **X-axis (Batch Size)**: Discrete values [8, 16, 32, 64, 128, 512] representing input batch sizes.
- **Y-axis (Accuracy %)**: Ranges from 30% to 90% across all charts.
- **Legends**: Positioned at the bottom-right of each chart, with color-coded labels:
- **Blue**: Gemini 1.5 Pro
- **Orange**: GPT 4 Turbo 20240409
- **Green**: Claude 3 Opus
---
### Detailed Analysis
#### 1. **Accuracy on Category Extraction**
- **Gemini 1.5 Pro**: Maintains near-constant accuracy (~90%) across all batch sizes.
- **GPT 4 Turbo 20240409**: Starts at ~85% (batch size 8), declines sharply after batch size 128, dropping to ~55% at 512.
- **Claude 3 Opus**: Begins at ~35% (batch size 8), collapses to ~25% by batch size 16, and vanishes below detection thresholds at larger sizes.
#### 2. **Accuracy on Color Extraction**
- **Gemini 1.5 Pro**: Stable ~90% accuracy across all batch sizes.
- **GPT 4 Turbo 20240409**: Starts at ~60% (batch size 8), declines to ~40% at 128, and ~30% at 512.
- **Claude 3 Opus**: Drops from ~25% (batch size 8) to ~20% at 16, then disappears at larger sizes.
#### 3. **Accuracy on Semantic Attribute Extraction**
- **Gemini 1.5 Pro**: Improves from ~65% (batch size 8) to ~75% (batch size 512), with minor fluctuations.
- **GPT 4 Turbo 20240409**: Declines from ~60% (batch size 8) to ~50% at 128, then plummets to ~40% at 512.
- **Claude 3 Opus**: Starts at ~55% (batch size 8), drops to ~45% at 16, and vanishes at larger sizes.
---
### Key Observations
1. **Gemini 1.5 Pro Dominance**: Consistently outperforms other models across all tasks and batch sizes, with minimal degradation as batch size increases.
2. **GPT 4 Turbo Degradation**: All models show significant accuracy drops beyond batch size 128, with GPT 4 Turbo experiencing the steepest decline in category and color extraction.
3. **Claude 3 Opus Fragility**: Performance collapses at batch sizes >16 in all tasks, suggesting poor scalability.
4. **Semantic Attribute Exception**: Gemini 1.5 Pro is the only model to improve accuracy with larger batch sizes in this task.
---
### Interpretation
The data demonstrates that **Gemini 1.5 Pro exhibits superior robustness and scalability** compared to GPT 4 Turbo and Claude 3 Opus. The sharp declines in GPT and Claude’s performance at larger batch sizes suggest architectural limitations in handling increased computational load. Notably, Gemini’s improvement in semantic attribute extraction with larger batches implies potential optimization for complex reasoning tasks. These trends highlight critical differences in model design philosophies, with Gemini prioritizing stability under load while others prioritize initial performance at smaller scales.