\n
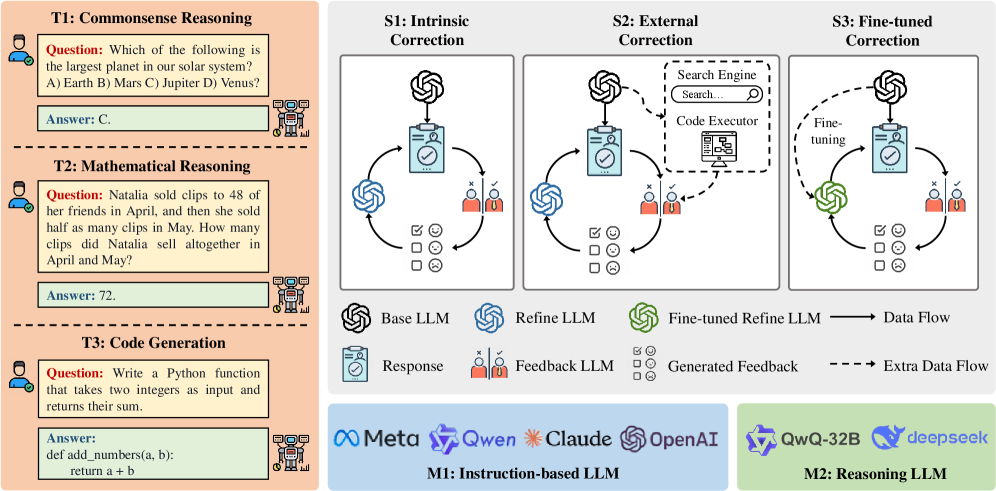
## Diagram: LLM Correction Strategies
### Overview
The image is a diagram illustrating different strategies for correcting Large Language Models (LLMs). It presents four distinct correction approaches (T1, S1, S2, S3) categorized by their method and the LLMs involved (M1, M2). The diagram visually represents the data flow and feedback loops within each strategy.
### Components/Axes
The diagram is divided into four main sections labeled T1 through T3 on the left, and S1 through S3 on the right. Below these are M1 and M2.
* **T1: Commonsense Reasoning:** Presents a question and answer related to commonsense knowledge.
* **T2: Mathematical Reasoning:** Presents a mathematical problem and its solution.
* **T3: Code Generation:** Presents a coding task and the generated code.
* **S1: Intrinsic Correction:** Shows a circular flow involving a Base LLM and a Refine LLM.
* **S2: External Correction:** Illustrates a process utilizing a Search Engine and Code Executor.
* **S3: Fine-tuned Correction:** Depicts a fine-tuning process with a Fine-tuned Refine LLM.
* **M1: Instruction-based LLM:** Lists Meta, Qwen, and Claude.
* **M2: Reasoning LLM:** Lists OpenAI, QwQ-32B, and deepseek.
* **Legend:** Icons represent different LLM types: Base LLM (grey swirl), Refine LLM (blue swirl), Fine-tuned Refine LLM (green swirl), Response (speech bubble), Feedback LLM (red person), Generated Feedback (red square with lines).
* **Data Flow:** Solid black arrows indicate the primary data flow.
* **Extra Data Flow:** Dashed black arrows indicate additional data flow.
### Detailed Analysis or Content Details
**T1: Commonsense Reasoning**
* **Question:** "Which of the following is the largest planet in our solar system? A) Earth B) Mars C) Jupiter D) Venus?"
* **Answer:** "C."
**T2: Mathematical Reasoning**
* **Question:** "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?"
* **Answer:** "72."
**T3: Code Generation**
* **Question:** "Write a Python function that takes two integers as input and returns their sum."
* **Answer:**
```python
def add_numbers(a, b):
return a + b
```
**S1: Intrinsic Correction**
* A Base LLM generates a response.
* The response is evaluated by a Feedback LLM.
* The Feedback LLM provides feedback to the Refine LLM.
* The Refine LLM generates a new response, completing a circular loop.
* Data flow is represented by a continuous circular arrow.
**S2: External Correction**
* A Base LLM generates a response.
* The response is sent to a Search Engine.
* The Search Engine provides information.
* The information is used by a Code Executor.
* The Code Executor provides feedback to the Refine LLM.
* The Refine LLM generates a new response.
* Data flow includes both continuous and dashed arrows, indicating external data input.
**S3: Fine-tuned Correction**
* A Base LLM generates a response.
* The response is evaluated by a Feedback LLM.
* The Feedback LLM provides feedback.
* The feedback is used to fine-tune a Refine LLM, creating a Fine-tuned Refine LLM.
* The Fine-tuned Refine LLM generates a new response.
* Data flow includes a continuous circular arrow and a dashed arrow representing the fine-tuning process.
**M1: Instruction-based LLM**
* Meta
* Qwen
* Claude
**M2: Reasoning LLM**
* OpenAI
* QwQ-32B
* deepseek
### Key Observations
* The diagram highlights a progression from intrinsic correction (S1) to external correction (S2) and finally to fine-tuned correction (S3).
* Each correction strategy involves a feedback loop, aiming to improve the LLM's output.
* The use of different LLM types (Base, Refine, Fine-tuned) suggests a modular approach to LLM correction.
* The inclusion of external tools like Search Engines and Code Executors indicates a reliance on external knowledge sources.
* The diagram clearly differentiates between data flow and extra data flow, emphasizing the importance of both internal and external feedback.
### Interpretation
The diagram demonstrates a multi-faceted approach to improving the accuracy and reliability of LLMs. The strategies presented range from self-correction through internal feedback loops (S1) to leveraging external resources (S2) and ultimately, refining the model itself through fine-tuning (S3). The categorization of LLMs into Instruction-based (M1) and Reasoning (M2) suggests a specialization of LLM capabilities. The diagram implies that a combination of these strategies may be necessary to achieve optimal LLM performance. The inclusion of specific LLM providers (Meta, OpenAI, etc.) suggests a practical application of these correction techniques within the current LLM landscape. The diagram is a conceptual overview, and doesn't provide quantitative data on the effectiveness of each strategy. However, it clearly articulates the different components and processes involved in LLM correction.