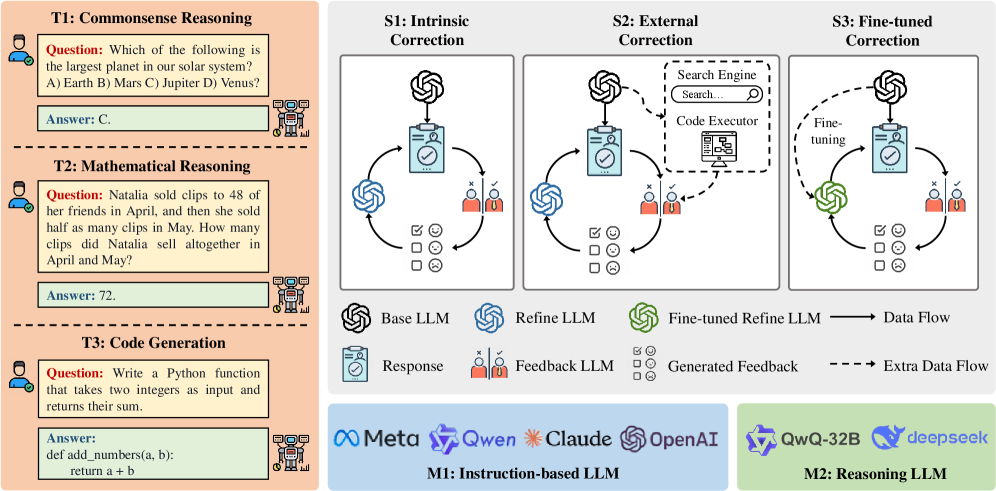
## Diagram: LLM Correction Methods and Task Examples
### Overview
The image is a technical diagram illustrating three different correction methods (S1, S2, S3) for Large Language Models (LLMs), alongside three example tasks (T1, T2, T3) that demonstrate the types of problems these methods might address. The diagram is divided into two primary sections: a left panel with task examples and a right panel detailing the correction workflows. A legend and model categorization are provided at the bottom.
### Components/Axes
**Left Panel (Task Examples):**
* **T1: Commonsense Reasoning**
* **Question:** "Which of the following is the largest planet in our solar system? A) Earth B) Mars C) Jupiter D) Venus?"
* **Answer:** "C."
* **T2: Mathematical Reasoning**
* **Question:** "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?"
* **Answer:** "72."
* **T3: Code Generation**
* **Question:** "Write a Python function that takes two integers as input and returns their sum."
* **Answer:** "def add_numbers(a, b): return a + b:"
**Right Panel (Correction Methods):**
* **S1: Intrinsic Correction**
* A cyclical process involving a "Base LLM" (black icon), a "Refine LLM" (blue icon), a "Response" (clipboard icon), and a "Feedback LLM" (two red figures icon). Arrows indicate a closed-loop data flow between these components.
* **S2: External Correction**
* Similar cyclical process to S1, but includes an external dashed box containing a "Search Engine" and a "Code Executor." An "Extra Data Flow" (dashed arrow) connects these external tools to the "Refine LLM."
* **S3: Fine-tuned Correction**
* Similar cyclical process, but the "Refine LLM" is replaced by a "Fine-tuned Refine LLM" (green icon). A dashed arrow labeled "Fine-tuning" points from the "Base LLM" to the "Fine-tuned Refine LLM."
**Legend (Bottom Right of Right Panel):**
* **Icons & Labels:**
* Black spiral icon: "Base LLM"
* Blue spiral icon: "Refine LLM"
* Green spiral icon: "Fine-tuned Refine LLM"
* Clipboard icon: "Response"
* Two red figures icon: "Feedback LLM"
* Three small squares icon: "Generated Feedback"
* **Arrows:**
* Solid black arrow: "Data Flow"
* Dashed black arrow: "Extra Data Flow"
**Model Categorization (Bottom of Image):**
* **M1: Instruction-based LLM** (Blue background)
* Logos/Names: Meta, Qwen, Claude, OpenAI
* **M2: Reasoning LLM** (Green background)
* Logos/Names: QwQ-32B, deepseek
### Detailed Analysis
The diagram presents a comparative view of LLM self-correction paradigms.
1. **Task Context (Left Panel):** The three tasks (T1-T3) represent common LLM evaluation benchmarks: factual recall, multi-step arithmetic, and functional code synthesis. They establish the problem domain where correction methods are applied.
2. **Correction Workflows (Right Panel):**
* **S1 (Intrinsic):** Shows a purely internal loop. The Base LLM generates a response, which is evaluated by a Feedback LLM. The generated feedback is then used by a Refine LLM to improve the response, creating a closed system.
* **S2 (External):** Augments the intrinsic loop by incorporating external tools (Search Engine, Code Executor). The Refine LLM can query these tools for factual verification or code execution, with the results flowing back as extra data to inform the refinement.
* **S3 (Fine-tuned):** Replaces the general Refine LLM with a specialized, fine-tuned version. The fine-tuning process is explicitly shown as a separate step originating from the Base LLM, suggesting the refinement model is a specialized derivative of the base model.
3. **Model Landscape (Bottom):** The diagram categorizes contemporary LLMs into two groups: "Instruction-based LLM" (M1), which includes major commercial and open-source models, and "Reasoning LLM" (M2), which lists specific models like QwQ-32B and DeepSeek, implying a focus on enhanced reasoning capabilities.
### Key Observations
* The core cyclical structure (Base LLM -> Response -> Feedback LLM -> Refine LLM -> back to Base LLM) is consistent across all three methods (S1, S2, S3), indicating a common architectural pattern for iterative correction.
* The primary differentiator between the methods is the source of refinement intelligence: internal models (S1), augmented by external tools (S2), or a specialized fine-tuned model (S3).
* The "Generated Feedback" icon (three squares) appears in all three workflows, positioned between the Feedback LLM and the Refine LLM, signifying the output of the evaluation step.
* The model categorization (M1 vs. M2) is presented separately from the correction methods, suggesting these are the types of base models that could be subjected to the S1/S2/S3 correction processes.
### Interpretation
This diagram serves as a conceptual framework for understanding how LLMs can be made to self-correct and improve their outputs. It argues that correction is not a single technique but a spectrum of approaches with increasing complexity and resource requirements.
* **S1 (Intrinsic)** represents a baseline, self-contained approach relying on the model's own knowledge and a separate feedback mechanism.
* **S2 (External)** acknowledges the limitations of an LLM's static knowledge and internal reasoning by integrating dynamic, real-world information and execution capabilities, making it suitable for tasks requiring up-to-date facts or verified code execution.
* **S3 (Fine-tuned)** suggests a more permanent, integrated solution where the refinement capability is baked into a specialized model, potentially offering more efficient and consistent corrections for specific domains.
The inclusion of the task examples (T1-T3) grounds these abstract methods in practical applications, showing the types of errors (factual, arithmetic, syntactic) each correction method might be designed to address. The model categorization at the bottom hints that the choice of base model (Instruction-based vs. Reasoning-focused) may influence the effectiveness of these correction strategies. Overall, the image maps a technical pathway from problem identification (tasks) to solution architectures (correction methods) within the current LLM ecosystem.