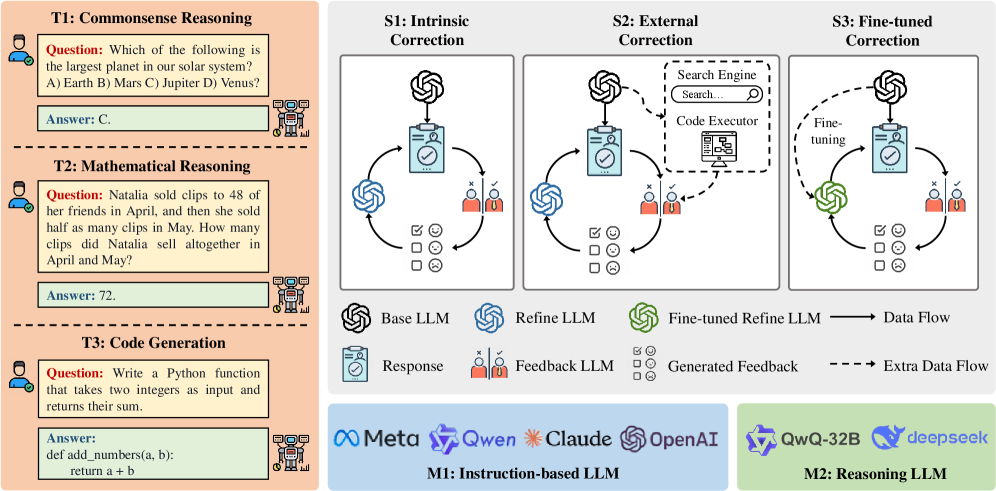
## Diagram: LLM Workflow and Correction Mechanisms
### Overview
The image presents a technical workflow diagram comparing three reasoning tasks (Commonsense, Mathematical, Code Generation) with three LLM correction strategies (Intrinsic, External, Fine-tuned). It includes component diagrams showing data flow between language models and external tools, along with categorization of different LLM architectures.
### Components/Axes
**Left Panel (Tasks):**
- **T1: Commonsense Reasoning**
- Question: "Which of the following is the largest planet in our solar system?"
- Options: A) Earth, B) Mars, C) Jupiter, D) Venus
- Answer: C
- **T2: Mathematical Reasoning**
- Question: "Natalia sold clips to 48 of her friends in April, then sold half as many clips in May. How many clips did Natalia sell altogether in April and May?"
- Answer: 72
- **T3: Code Generation**
- Question: "Write a Python function that takes two integers as input and returns their sum."
- Answer: `def add_numbers(a, b): return a + b`
**Right Panel (Correction Strategies):**
- **S1: Intrinsic Correction**
- Components: Base LLM → Refine LLM
- Data Flow: Response → Feedback LLM → Generated Feedback
- **S2: External Correction**
- Components: Base LLM → Search Engine → Code Executor
- Data Flow: Response → External Tools → Refine LLM
- **S3: Fine-tuned Correction**
- Components: Base LLM → Fine-tuned Refine LLM
- Data Flow: Response → Fine-tuning → Refine LLM
**Bottom Panel (LLM Architectures):**
- **M1: Instruction-based LLM**
- Models: Meta, Qwen, Claude, OpenAI
- **M2: Reasoning LLM**
- Models: QwQ-32B, DeepSeek
**Legend:**
- Blue circles: Base LLM
- Green circles: Refine LLM
- Dashed lines: Extra Data Flow
- Solid arrows: Primary Data Flow
- Red icons: External Tools (Search Engine, Code Executor)
### Detailed Analysis
**Task Section (Left):**
- All tasks follow a consistent format: Question → Options → Answer
- Mathematical reasoning requires numerical computation (April: 48 clips, May: 24 clips → Total: 72)
- Code generation demonstrates Python syntax understanding
**Correction Strategies (Right):**
1. **Intrinsic Correction (S1):**
- Direct refinement within the LLM architecture
- Feedback loop between Base and Refine LLM
- No external tools involved
2. **External Correction (S2):**
- Integrates external tools (Search Engine, Code Executor)
- Two-stage process: Initial response → External validation → Refinement
- Most complex data flow with multiple feedback points
3. **Fine-tuned Correction (S3):**
- Model-specific optimization through fine-tuning
- Direct connection between Base and Refine LLM
- Simplest data flow but requires model adaptation
**LLM Categorization (Bottom):**
- Instruction-based models (M1) focus on task execution
- Reasoning models (M2) emphasize problem-solving capabilities
- Color coding distinguishes model types and data flows
### Key Observations
1. **Data Flow Complexity:**
- External correction shows the most complex workflow with multiple feedback loops
- Fine-tuned correction has the simplest but most specialized data path
2. **LLM Specialization:**
- Reasoning LLMs (M2) appear focused on problem-solving tasks
- Instruction-based models (M1) handle general task execution
3. **Correction Strategy Tradeoffs:**
- Intrinsic correction balances simplicity and effectiveness
- External correction offers maximum adaptability but requires external resources
- Fine-tuned correction provides optimal performance at the cost of model specificity
### Interpretation
The diagram illustrates a framework for evaluating and improving LLM performance through different correction mechanisms. The three correction strategies represent increasing levels of complexity and specialization:
1. **Intrinsic Correction** demonstrates basic self-improvement capabilities within the model architecture
2. **External Correction** shows how LLMs can leverage external tools for enhanced reasoning
3. **Fine-tuned Correction** represents the most advanced approach, requiring model adaptation for specific tasks
The categorization of LLMs into instruction-based and reasoning types suggests a taxonomy where:
- Instruction-based models excel at following explicit commands
- Reasoning models demonstrate stronger problem-solving abilities
The color-coded data flows emphasize the importance of feedback mechanisms in LLM development. The external correction path's complexity highlights the challenges of integrating external tools while maintaining coherent data flow. This framework provides a comprehensive approach to LLM evaluation, balancing model architecture, correction strategies, and task-specific requirements.