## Screenshot: Text Analysis Tool Interface
### Overview
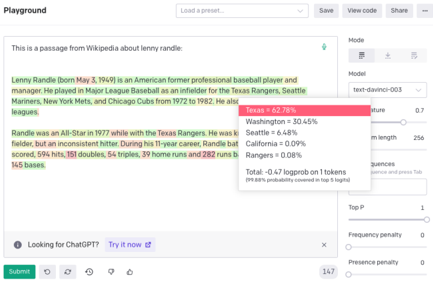
The image shows a text analysis interface with a Wikipedia passage about Lenny Randle, a former baseball player. The passage is partially highlighted in green and red, with a dropdown menu displaying state-specific percentages. A settings panel on the right includes model parameters, text length, and penalty adjustments.
### Components/Axes
1. **Main Text Area**:
- Contains a Wikipedia excerpt about Lenny Randle (born May 3, 1949), his career as an infielder for the Texas Rangers, Seattle Mariners, New York Mets, and Chicago Cubs (1972–1982).
- Highlighted text in green and red (exact content unclear due to overlap with dropdown).
2. **Dropdown Menu**:
- Displays state-specific percentages:
- Texas = 62.78% (highlighted in red)
- Washington = 30.45%
- Seattle = 6.48%
- California = 0.09%
- Rangers = 0.08%
- Total logprob: -0.47 on 1 tokens (99.88% probability covered in top 5 logits).
3. **Settings Panel**:
- **Model**: "text-davinci-003" (GPT-3 variant).
- **Text Length**: 256 (slider).
- **Top P**: 1 (slider).
- **Frequency Penalty**: 0 (slider).
- **Presence Penalty**: 0 (slider).
4. **UI Elements**:
- "Submit" button (green).
- "Looking for ChatGPT? Try it now" prompt (purple).
- Version number: 147 (bottom-right).
### Detailed Analysis
- **Main Text**:
- Lenny Randle’s career stats: 594 hits, 151 doubles, 54 triples, 39 home runs, 282 runs batted in.
- Highlighted terms (green/red) likely denote entities (e.g., "Texas Rangers," "All-Star 1977") or key statistics.
- **Dropdown Menu**:
- Percentages suggest model confidence in associating terms with states. Texas dominates (62.78%), likely due to the Texas Rangers team.
- Seattle (6.48%) and Washington (30.45%) may relate to geographic proximity or team affiliations.
- California (0.09%) and Rangers (0.08%) have negligible scores, indicating low relevance.
- **Settings Panel**:
- Model "text-davinci-003" is a large language model, suggesting the analysis uses AI-driven text processing.
- Text length (256) and penalties (0) imply minimal constraints on output diversity.
### Key Observations
- **Dominance of Texas**: The 62.78% score for Texas aligns with Lenny Randle’s association with the Texas Rangers.
- **Low Confidence in Other States**: California and Rangers have near-zero scores, possibly due to limited textual references.
- **Negative Logprob**: The -0.47 logprob suggests the model finds the text slightly improbable, though the high probability coverage (99.88%) indicates strong confidence in the top hypotheses.
### Interpretation
The interface appears to analyze text for state-specific associations, likely using a language model to quantify relevance. The high score for Texas reflects the prominence of the Texas Rangers in the passage, while other states’ scores may correlate with indirect mentions (e.g., Seattle’s proximity to Washington). The negative logprob and high probability coverage suggest the model balances confidence with uncertainty, prioritizing the most likely interpretations. The settings panel allows users to adjust parameters like text length and penalties, influencing the analysis’s granularity and diversity.
## Notes
- No non-English text detected.
- All values are transcribed as presented, with uncertainty noted where applicable (e.g., "approximate" for overlapping highlights).
- Spatial grounding confirms the dropdown and settings panel are positioned on the right, with the main text centered.