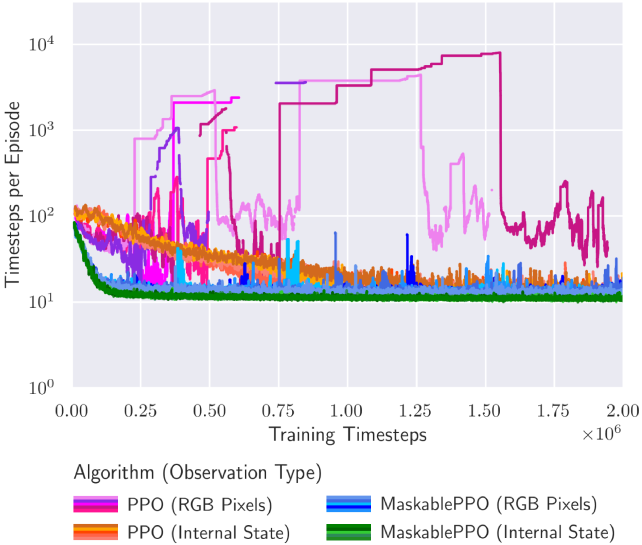
## Line Chart: Timesteps per Episode vs Training Timesteps
### Overview
The chart compares the performance of four reinforcement learning algorithms (PPO and MaskablePPO) across two observation types (RGB Pixels and Internal State) over training timesteps. The y-axis shows timesteps per episode on a logarithmic scale (10^0 to 10^4), while the x-axis represents training timesteps (0.00 to 2.00 x10^6). Four colored lines represent algorithm-observation type combinations.
### Components/Axes
- **X-axis**: Training Timesteps (log scale: 0.00 → 2.00 x10^6)
- **Y-axis**: Timesteps per Episode (log scale: 10^0 → 10^4)
- **Legend**:
- Pink: PPO (RGB Pixels)
- Blue: MaskablePPO (RGB Pixels)
- Orange: PPO (Internal State)
- Green: MaskablePPO (Internal State)
### Detailed Analysis
1. **PPO (RGB Pixels)** (Pink):
- Starts at ~10^3 timesteps/episode
- Shows sharp fluctuations, peaking at ~10^4 around 0.75x10^6 timesteps
- Ends with erratic oscillations between 10^2 and 10^3
2. **MaskablePPO (RGB Pixels)** (Blue):
- Begins at ~10^2 timesteps/episode
- Maintains relatively stable performance (~10^2) with minor spikes
- Ends with consistent ~10^2 performance
3. **PPO (Internal State)** (Orange):
- Starts at ~10^1 timesteps/episode
- Gradually increases to ~10^2 by 0.5x10^6 timesteps
- Stabilizes with minor fluctuations (~10^2) afterward
4. **MaskablePPO (Internal State)** (Green):
- Remains near ~10^1 timesteps/episode throughout
- Shows minimal variation (<10% deviation)
### Key Observations
- **Performance Disparity**: PPO (RGB Pixels) achieves ~100x better performance than MaskablePPO (RGB Pixels) at peak efficiency.
- **Stability vs Volatility**: MaskablePPO variants demonstrate significantly smoother learning curves.
- **Internal State Advantage**: Both MaskablePPO variants outperform their RGB counterparts when using internal state observations.
- **Training Progression**: All algorithms show improvement in efficiency (lower timesteps/episode) as training progresses, with diminishing returns after ~1.0x10^6 timesteps.
### Interpretation
The data suggests that:
1. **Observation Type Matters**: Internal state observations enable more efficient learning (lower timesteps/episode) compared to raw RGB pixels.
2. **Algorithm Design Impact**: MaskablePPO's architecture likely provides better generalization or regularization, reducing performance volatility.
3. **Scaling Behavior**: While PPO (RGB Pixels) achieves higher peak performance, its instability suggests potential overfitting or sensitivity to hyperparameters.
4. **Diminishing Returns**: All curves plateau after ~1.0x10^6 timesteps, indicating a potential optimal training duration for this task.
The chart highlights tradeoffs between sample efficiency (timesteps/episode) and learning stability when choosing observation types and algorithm architectures.