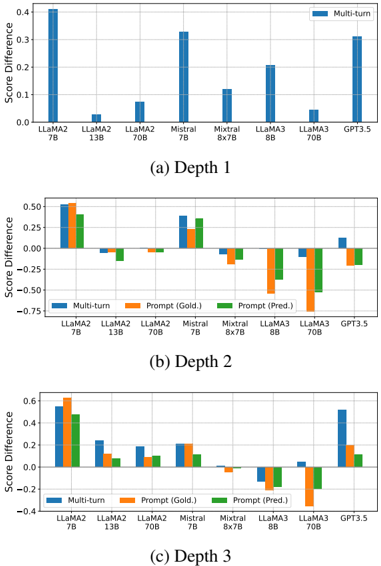
## Bar Chart: Score Difference at Different Depths
### Overview
The image contains three bar charts, each representing the score difference for various language models at different depths (Depth 1, Depth 2, and Depth 3). The x-axis represents the language models, and the y-axis represents the score difference. The charts compare "Multi-turn", "Prompt (Gold.)", and "Prompt (Pred.)" scores for each model.
### Components/Axes
* **Y-axis (Score Difference):** Ranges from approximately -0.75 to 0.6, with increments of 0.25 or 0.2.
* **X-axis:** Represents different language models: LLaMA2 7B, LLaMA2 13B, LLaMA2 70B, Mistral 7B, Mistral 8x7B, LLaMA3 8B, LLaMA3 70B, and GPT3.5.
* **Legend:** Located at the top-right of the first chart and in the middle of the second and third charts.
* Blue: Multi-turn
* Orange: Prompt (Gold.)
* Green: Prompt (Pred.)
* **Titles:** Each chart has a title indicating the depth: (a) Depth 1, (b) Depth 2, (c) Depth 3.
### Detailed Analysis
#### (a) Depth 1
* **LLaMA2 7B:** Multi-turn score difference is approximately 0.4.
* **LLaMA2 13B:** Multi-turn score difference is approximately 0.0.
* **LLaMA2 70B:** Multi-turn score difference is approximately 0.08.
* **Mistral 7B:** Multi-turn score difference is approximately 0.33.
* **Mistral 8x7B:** Multi-turn score difference is approximately 0.12.
* **LLaMA3 8B:** Multi-turn score difference is approximately 0.20.
* **LLaMA3 70B:** Multi-turn score difference is approximately 0.0.
* **GPT3.5:** Multi-turn score difference is approximately 0.25.
#### (b) Depth 2
* **LLaMA2 7B:**
* Multi-turn: ~0.5
* Prompt (Gold.): ~0.55
* Prompt (Pred.): ~0.45
* **LLaMA2 13B:**
* Multi-turn: ~-0.1
* Prompt (Gold.): ~-0.1
* Prompt (Pred.): ~-0.1
* **LLaMA2 70B:**
* Multi-turn: ~-0.05
* Prompt (Gold.): ~-0.05
* Prompt (Pred.): ~-0.1
* **Mistral 7B:**
* Multi-turn: ~0.4
* Prompt (Gold.): ~0.3
* Prompt (Pred.): ~0.35
* **Mistral 8x7B:**
* Multi-turn: ~-0.15
* Prompt (Gold.): ~-0.2
* Prompt (Pred.): ~-0.2
* **LLaMA3 8B:**
* Multi-turn: ~-0.5
* Prompt (Gold.): ~-0.6
* Prompt (Pred.): ~-0.3
* **LLaMA3 70B:**
* Multi-turn: ~-0.4
* Prompt (Gold.): ~-0.4
* Prompt (Pred.): ~-0.5
* **GPT3.5:**
* Multi-turn: ~0.15
* Prompt (Gold.): ~-0.1
* Prompt (Pred.): ~-0.15
#### (c) Depth 3
* **LLaMA2 7B:**
* Multi-turn: ~0.55
* Prompt (Gold.): ~0.6
* Prompt (Pred.): ~0.45
* **LLaMA2 13B:**
* Multi-turn: ~0.25
* Prompt (Gold.): ~0.1
* Prompt (Pred.): ~0.2
* **LLaMA2 70B:**
* Multi-turn: ~0.15
* Prompt (Gold.): ~0.1
* Prompt (Pred.): ~0.1
* **Mistral 7B:**
* Multi-turn: ~0.2
* Prompt (Gold.): ~0.2
* Prompt (Pred.): ~0.1
* **Mistral 8x7B:**
* Multi-turn: ~-0.1
* Prompt (Gold.): ~-0.1
* Prompt (Pred.): ~-0.1
* **LLaMA3 8B:**
* Multi-turn: ~-0.1
* Prompt (Gold.): ~-0.1
* Prompt (Pred.): ~-0.2
* **LLaMA3 70B:**
* Multi-turn: ~-0.2
* Prompt (Gold.): ~-0.1
* Prompt (Pred.): ~-0.3
* **GPT3.5:**
* Multi-turn: ~0.4
* Prompt (Gold.): ~0.1
* Prompt (Pred.): ~0.1
### Key Observations
* **Depth 1:** Multi-turn scores are generally positive for all models.
* **Depth 2:** Some models have negative score differences, particularly LLaMA3 8B and LLaMA3 70B.
* **Depth 3:** The score differences vary, with some models showing positive and others showing negative differences.
* LLaMA2 7B consistently has high scores across all depths.
* LLaMA3 models tend to have lower or negative scores at Depth 2 and Depth 3.
### Interpretation
The charts compare the performance of different language models across varying depths, likely referring to the depth of reasoning or interaction within a task. The "Multi-turn" scores likely represent performance in a conversational or multi-step task. "Prompt (Gold.)" and "Prompt (Pred.)" likely refer to performance based on a gold-standard prompt and a predicted prompt, respectively.
The data suggests that some models, like LLaMA2 7B, perform well across all depths and prompting strategies. Other models, like LLaMA3 8B and 70B, struggle at deeper levels, indicating potential limitations in their reasoning or interaction capabilities. The differences between "Prompt (Gold.)" and "Prompt (Pred.)" highlight the impact of prompt quality on model performance. The negative score differences at Depth 2 and Depth 3 for some models suggest that their performance degrades as the task becomes more complex or requires deeper reasoning.