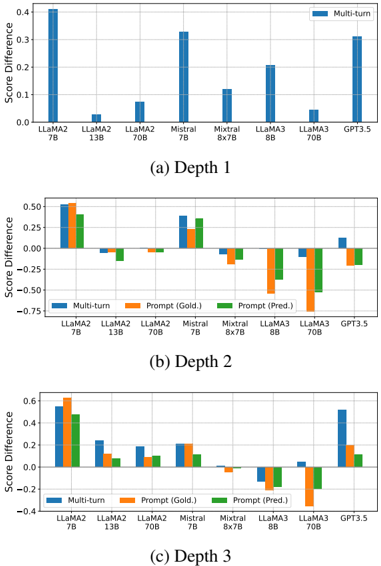
## Bar Chart: Model Performance Across Interaction Depths
### Overview
The image contains three vertically stacked bar charts comparing model performance across three interaction depths (Depth 1, Depth 2, Depth 3). Each chart evaluates models (LLaMA2, Mistral, Mixtral, LLaMA3, GPT-3.5) using three metrics: Multi-turn, Prompt (Gold.), and Prompt (Pred.). The y-axis measures "Score Difference" (range: -0.75 to 0.6), while the x-axis lists models with parameter sizes (e.g., LLaMA2 7B, LLaMA3 8B).
### Components/Axes
- **X-axis**: Model names with parameter sizes (e.g., LLaMA2 7B, LLaMA3 8B)
- **Y-axis**: Score Difference (range: -0.75 to 0.6)
- **Legend**:
- Blue: Multi-turn
- Orange: Prompt (Gold.)
- Green: Prompt (Pred.)
- **Chart Titles**:
- (a) Depth 1
- (b) Depth 2
- (c) Depth 3
### Detailed Analysis
#### Depth 1
- **Multi-turn**:
- LLaMA2 7B: ~0.4
- Mistral 7B: ~0.3
- GPT-3.5: ~0.3
- **Prompt (Gold.)**:
- LLaMA2 7B: ~0.5
- LLaMA2 13B: ~0.05
- LLaMA2 70B: ~0.08
- **Prompt (Pred.)**:
- LLaMA2 7B: ~0.4
- LLaMA2 13B: ~-0.05
- LLaMA2 70B: ~0.05
#### Depth 2
- **Multi-turn**:
- LLaMA2 7B: ~0.25
- Mixtral 8x7B: ~0.1
- LLaMA3 8B: ~0.2
- **Prompt (Gold.)**:
- LLaMA2 7B: ~0.25
- LLaMA3 8B: ~-0.1
- LLaMA3 70B: ~-0.3
- **Prompt (Pred.)**:
- LLaMA2 7B: ~0.3
- LLaMA3 8B: ~-0.15
- LLaMA3 70B: ~-0.25
#### Depth 3
- **Multi-turn**:
- LLaMA2 7B: ~0.2
- LLaMA3 8B: ~-0.05
- GPT-3.5: ~0.05
- **Prompt (Gold.)**:
- LLaMA2 7B: ~0.2
- LLaMA3 8B: ~-0.2
- LLaMA3 70B: ~-0.4
- **Prompt (Pred.)**:
- LLaMA2 7B: ~0.1
- LLaMA3 8B: ~-0.1
- LLaMA3 70B: ~-0.3
### Key Observations
1. **Multi-turn Consistency**: Multi-turn scores remain relatively stable across depths, with LLaMA2 7B consistently highest (~0.4 in Depth 1, ~0.25 in Depth 2, ~0.2 in Depth 3).
2. **Prompt Performance Decline**: Prompt (Gold.) and (Pred.) scores generally decrease with increasing depth, particularly for LLaMA3 models (e.g., LLaMA3 70B drops from ~-0.3 in Depth 2 to ~-0.4 in Depth 3).
3. **Outliers**:
- LLaMA3 8B shows negative scores in Depth 2/3 for Prompt (Gold.) and (Pred.).
- GPT-3.5's Prompt (Gold.) score improves slightly in Depth 3 (~0.05 vs. ~0.2 in Depth 1).
### Interpretation
The data suggests that **multi-turn interactions** maintain higher performance across all depths compared to prompt-based evaluations. The decline in Prompt (Gold.) and (Pred.) scores with increasing depth indicates potential limitations in handling complex, multi-step reasoning tasks. Notably, larger models (e.g., LLaMA3 70B) underperform in prompt-based metrics at deeper depths, possibly due to architectural constraints or training data gaps. GPT-3.5's mixed performance highlights its variable effectiveness across interaction types. These trends underscore the importance of interaction design in leveraging model capabilities for specific applications.