\n
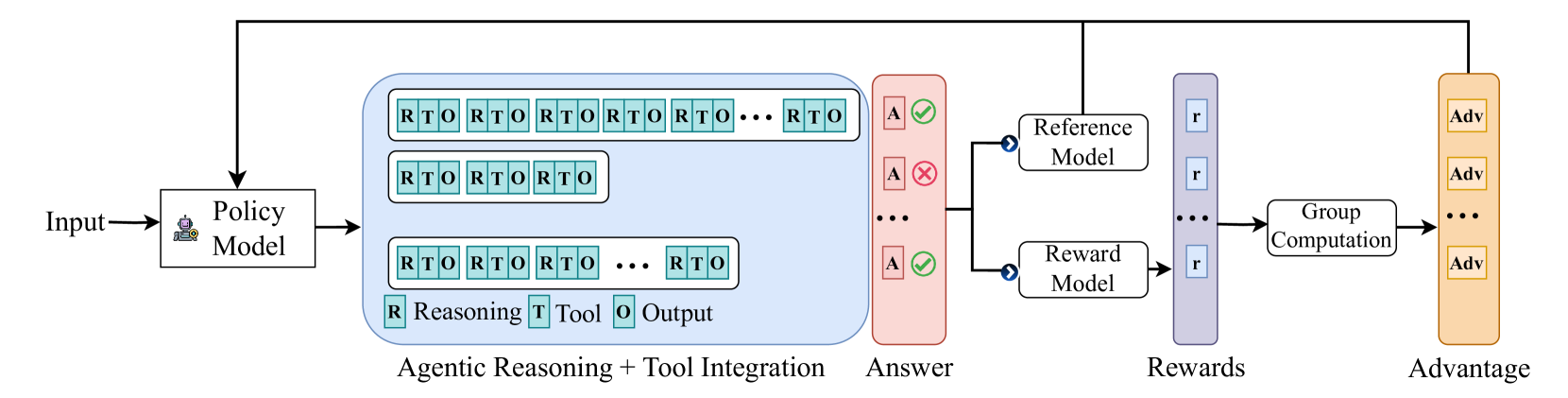
## Diagram: Agentic Reasoning + Tool Integration
### Overview
The image is a diagram illustrating a system for agentic reasoning and tool integration. It depicts a process flow starting with an "Input", passing through a "Policy Model", generating an "Answer", and then calculating "Rewards" and "Advantage". The diagram highlights the iterative nature of reasoning and tool use within the policy model.
### Components/Axes
The diagram consists of the following components:
* **Input:** The starting point of the process.
* **Policy Model:** A rectangular block containing multiple layers of "RTO" (Reasoning, Tool, Output) sequences.
* **Agentic Reasoning + Tool Integration:** A label describing the functionality of the Policy Model.
* **Answer:** The output generated by the Policy Model.
* **Reference Model:** A block that receives the "Answer" and outputs a validation indicator ("A" with a checkmark or cross).
* **Reward Model:** A block that receives the "Answer" and outputs "Rewards" ("r").
* **Group Computation:** A block that receives "Rewards" and outputs "Advantage" ("Adv").
* **Rewards:** The output of the Reward Model.
* **Advantage:** The output of the Group Computation.
The diagram also includes labels within the Policy Model:
* **R:** Reasoning
* **T:** Tool
* **O:** Output
### Detailed Analysis or Content Details
The Policy Model is the most complex component. It consists of three horizontal layers, each containing a sequence of "RTO" blocks.
* **Layer 1:** Contains a longer sequence of "RTO" blocks, extending to "..." indicating continuation.
* **Layer 2:** Contains a shorter sequence of "RTO" blocks.
* **Layer 3:** Contains a sequence of "RTO" blocks, followed by "R", "T", "O".
The "Answer" is generated from the Policy Model and is fed into both the "Reference Model" and the "Reward Model". The Reference Model outputs "A" with either a checkmark (positive validation) or a cross (negative validation). The Reward Model outputs "r", which represents the reward signal. The "Rewards" are then processed by the "Group Computation" block to produce "Advantage", represented by "Adv".
### Key Observations
* The iterative "RTO" structure within the Policy Model suggests a cyclical process of reasoning, tool application, and output generation.
* The parallel processing of the "Answer" through the Reference and Reward Models indicates a dual evaluation of the generated output – both for correctness (Reference Model) and value (Reward Model).
* The "Group Computation" step implies that the "Advantage" is derived from a collective assessment of the "Rewards".
* The "..." notation suggests that the process can continue indefinitely, with the Policy Model refining its reasoning and tool usage over time.
### Interpretation
This diagram illustrates a reinforcement learning framework for agentic reasoning. The agent (represented by the Policy Model) interacts with an environment (implicitly represented by the "Tool" component) to achieve a goal. The agent's actions are evaluated by both a Reference Model (ensuring correctness) and a Reward Model (quantifying progress). The Advantage signal is then used to update the Policy Model, guiding it towards more effective reasoning and tool usage. The iterative "RTO" loop suggests a process of trial and error, where the agent learns from its mistakes and refines its strategy over time. The diagram highlights the importance of both accuracy and reward in shaping the agent's behavior. The use of a Reference Model alongside a Reward Model is a notable feature, suggesting a focus on both correctness and efficiency in the agent's decision-making process. The diagram does not provide specific data or numerical values, but rather a conceptual overview of the system's architecture and functionality.