\n
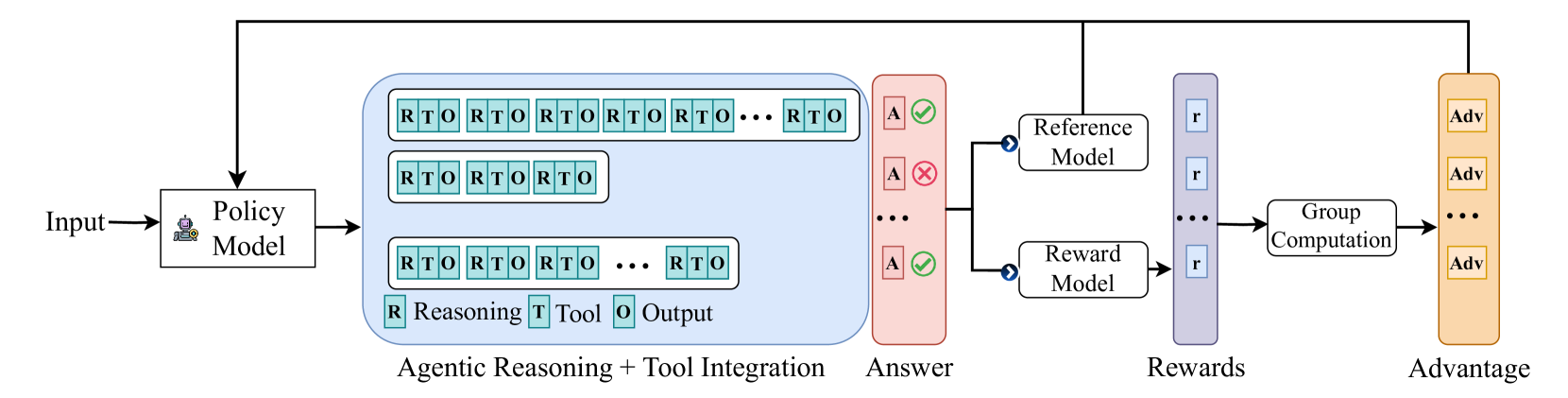
## Diagram: Agentic Reasoning and Reinforcement Learning Pipeline
### Overview
The image is a technical flowchart illustrating a machine learning or AI training pipeline. It depicts a process where an input is processed by a policy model to generate multiple reasoning-tool-output sequences, which are then evaluated, scored, and used to compute advantages for model improvement. The flow moves from left to right, with a feedback loop from the final "Advantage" stage back to the initial "Policy Model."
### Components/Axes
The diagram is composed of several distinct, color-coded blocks connected by directional arrows.
1. **Input**: A simple text label on the far left, indicating the starting point of the process.
2. **Policy Model**: A white rectangular box with a small robot icon. It receives the "Input" and outputs to the next stage.
3. **Agentic Reasoning + Tool Integration (Blue Box)**: A large, light-blue rounded rectangle containing the core generative process.
* **Content**: It contains three horizontal rows of blocks. Each row is a sequence of smaller, connected teal-colored blocks labeled "RTO".
* **Legend**: At the bottom of this blue box, a legend defines the components of each "RTO" block:
* **R** (in a teal square): Reasoning
* **T** (in a teal square): Tool
* **O** (in a teal square): Output
* **Structure**: The top and bottom rows show long sequences ending with "... RTO", indicating variable length. The middle row shows a shorter sequence of three "RTO" blocks.
4. **Answer (Red Box)**: A tall, light-red rounded rectangle to the right of the blue box.
* **Content**: It contains a vertical column of items labeled "A". Each "A" is accompanied by a status icon: a green checkmark (✓) or a red cross (✗). The diagram shows two checkmarks and one cross, with ellipsis (...) indicating more items.
5. **Reference Model & Reward Model**: Two white rectangular boxes stacked vertically.
* The "Answer" box feeds into both models via a branching arrow.
6. **Rewards (Purple Box)**: A tall, light-purple rounded rectangle.
* **Content**: It contains a vertical column of items labeled "r", corresponding to the outputs from the Reward Model. Ellipsis (...) indicates a sequence.
7. **Group Computation**: A white rectangular box that receives the sequence of "r" values from the "Rewards" box.
8. **Advantage (Orange Box)**: A tall, light-orange rounded rectangle on the far right.
* **Content**: It contains a vertical column of items labeled "Adv", representing the computed advantages. Ellipsis (...) indicates a sequence.
9. **Feedback Loop**: A black arrow originates from the top of the "Advantage" box, travels left across the top of the entire diagram, and points down into the "Policy Model", indicating an iterative training or optimization process.
### Detailed Analysis
* **Flow Direction**: The primary data flow is linear from left to right: Input → Policy Model → Agentic Reasoning → Answer → Models → Rewards → Group Computation → Advantage.
* **Process Logic**:
1. The **Policy Model** generates multiple candidate response sequences (the "RTO" chains) for a given input.
2. These sequences result in final **Answers** ("A"), which are evaluated as correct (✓) or incorrect (✗).
3. The answers are processed by a **Reference Model** and a **Reward Model**. The Reward Model produces scalar reward signals ("r").
4. The individual rewards are aggregated via **Group Computation**.
5. This computation yields **Advantage** ("Adv") values, which likely measure how much better a given response was compared to the group average.
6. The advantage values are fed back to update the **Policy Model**, completing the reinforcement learning cycle.
### Key Observations
* **Multiple Candidates**: The system explicitly generates and evaluates multiple reasoning paths (the three "RTO" rows) for a single input, suggesting a best-of-n or group-based sampling strategy.
* **Explicit Reasoning-Tool-Output Structure**: The "RTO" breakdown indicates a modular approach where reasoning steps, tool calls, and their outputs are distinct, sequential components of the generation process.
* **Evaluation and Reward**: The pipeline separates answer verification (✓/✗) from reward modeling ("r"), which is a common setup in reinforcement learning from human feedback (RLHF) or similar paradigms.
* **Group-Based Advantage**: The "Group Computation" step leading to "Advantage" suggests the use of algorithms like REINFORCE with baseline or Group Relative Policy Optimization (GRPO), where advantages are computed relative to a group of samples.
### Interpretation
This diagram illustrates a sophisticated training or inference pipeline for an AI agent capable of complex, tool-augmented reasoning. The core innovation appears to be the tight integration of explicit reasoning steps ("R") with tool usage ("T") and their outputs ("O") into a single, optimizable sequence.
The process is designed to move beyond simple supervised learning. By generating multiple candidate solutions, evaluating their final answers, and computing relative advantages, the system can learn which reasoning-tool trajectories lead to correct outcomes. The feedback loop enables the Policy Model to iteratively improve, favoring the generation of high-reward "RTO" sequences.
The presence of both a "Reference Model" and a "Reward Model" hints at a two-stage evaluation: the reference model might provide a baseline or preference ranking, while the reward model assigns a scalar score. The final "Advantage" signal is the key driver for policy update, pushing the model to produce reasoning chains that are not just correct, but also efficient and effective compared to its own previous attempts. This architecture is typical of advanced systems aiming for robust, multi-step problem-solving in domains like mathematics, coding, or scientific inquiry.