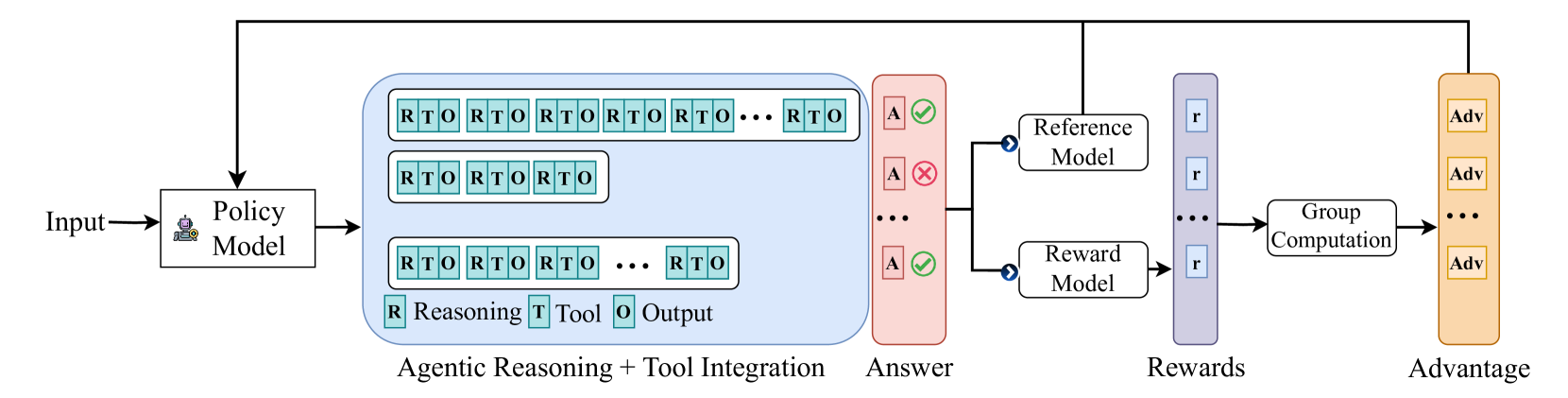
## Flowchart: System Architecture for Policy Model with Agentic Reasoning and Reward Evaluation
### Overview
The flowchart depicts a multi-stage system architecture for processing input through a policy model, incorporating agentic reasoning, tool integration, and reward-based evaluation. The flow progresses from left to right, with feedback loops and parallel processing paths.
### Components/Axes
1. **Input**: Starting point labeled "Input" with an arrow pointing to the Policy Model.
2. **Policy Model**: Processes input and generates outputs for three parallel streams:
- **Agentic Reasoning + Tool Integration**: Contains repeated "RTO" blocks (Reasoning-Tool-Output) with ellipses indicating repetition.
- **Answer**: Contains three "A" blocks with mixed checkmarks (✓) and crosses (✗).
3. **Reference Model**: Receives input from the Answer component via a blue arrow.
4. **Reward Model**: Receives input from the Answer component via a blue arrow.
5. **Group Computation**: Receives inputs from both Reference and Reward Models via purple arrows.
6. **Advantage**: Final output component with three "Adv" blocks.
### Detailed Analysis
- **Agentic Reasoning + Tool Integration**:
- Contains three rows of RTO blocks:
- Top row: 6 RTO blocks (RTO RTO RTO RTO RTO RTO...)
- Middle row: 3 RTO blocks
- Bottom row: 4 RTO blocks (RTO RTO RTO...)
- Each RTO block contains three sub-components: Reasoning (R), Tool (T), Output (O)
- **Answer Component**:
- Three "A" blocks with alternating checkmarks and crosses:
- Top: ✓
- Middle: ✗
- Bottom: ✓
- **Reward and Reference Models**:
- Both receive input from the Answer component via blue arrows
- Reward Model outputs purple "r" blocks
- Reference Model outputs purple "r" blocks
- **Group Computation**:
- Receives inputs from both models via purple arrows
- Outputs to Advantage component
- **Advantage**:
- Contains three "Adv" blocks in orange
### Key Observations
1. The system employs parallel processing with feedback loops
2. The Answer component serves as a critical evaluation point with explicit success/failure indicators
3. Multiple RTO blocks suggest iterative reasoning and tool usage
4. The final Advantage component aggregates information from both reference and reward models
### Interpretation
This architecture demonstrates a complex decision-making system where:
1. The Policy Model initiates processing but defers complex reasoning to specialized components
2. Agentic reasoning with tool integration occurs through multiple RTO cycles, suggesting iterative problem-solving
3. The Answer component acts as a quality control checkpoint with explicit validation
4. The Reference and Reward Models provide complementary evaluations that are combined through group computation
5. The final Advantage component represents the system's optimized output, balancing both reference accuracy and reward optimization
The use of checkmarks/crosses in the Answer component implies a binary evaluation system, while the multiple RTO blocks suggest that complex reasoning tasks require multiple processing cycles. The parallel processing paths indicate that the system can handle multiple evaluation dimensions simultaneously before converging on a final output.