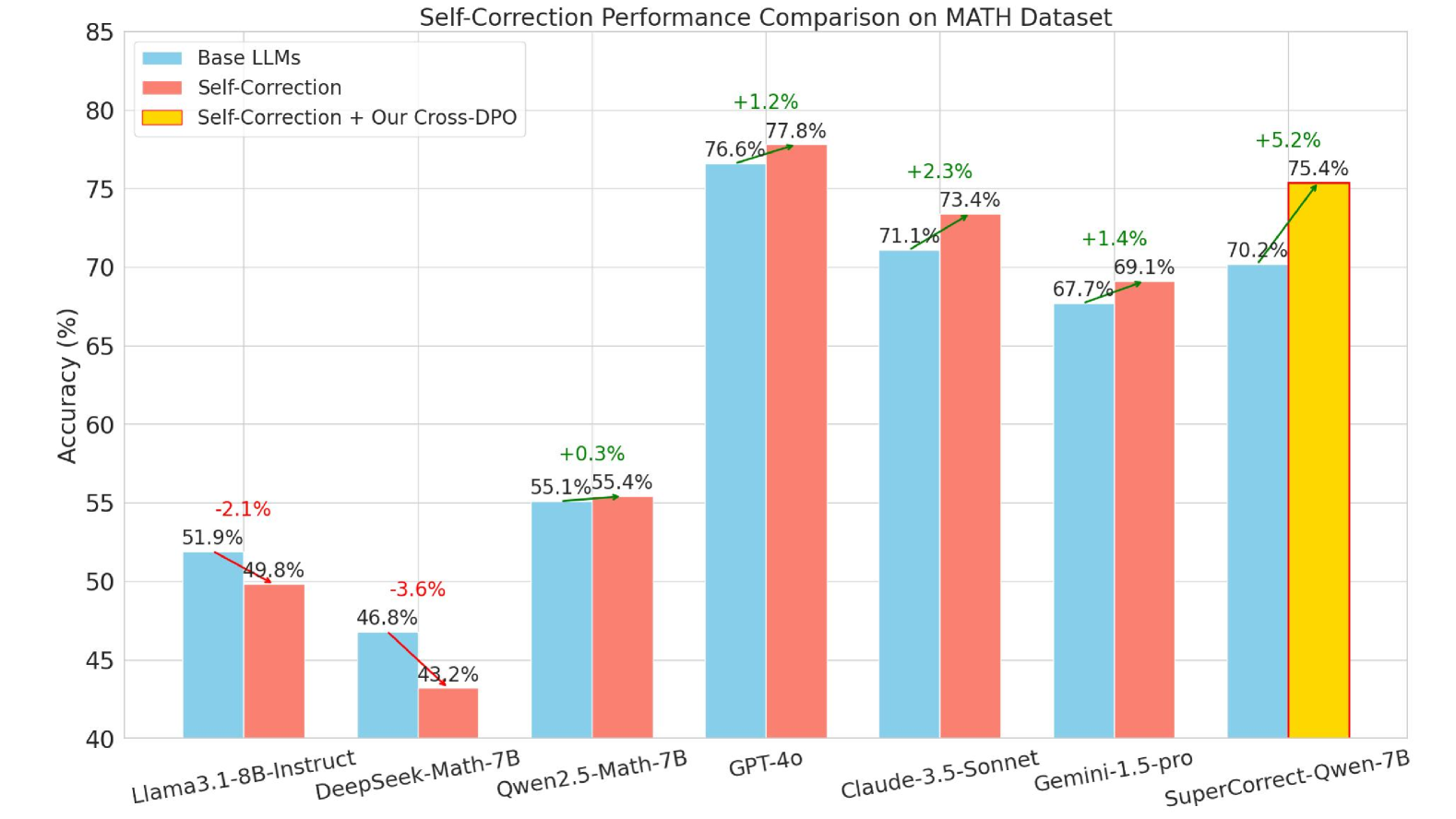
## Bar Chart: Self-Correction Performance Comparison on MATH Dataset
### Overview
The bar chart compares the accuracy of different language models (LLMs) on a MATH dataset after applying self-correction techniques. The chart shows the baseline accuracy, self-correction accuracy, and the accuracy after applying self-correction with a cross-DPO method.
### Components/Axes
- **X-axis**: List of different language models: Llama3.1-8B-Instruct, DeepSeek-Math-7B, Qwen2.5-Math-7B, GPT-40, Claude-3.5-Sonnet, Gemini-1.5-pro, SuperCorrect-Qwen-7B.
- **Y-axis**: Accuracy percentage, ranging from 40% to 85%.
- **Legend**: Three categories of accuracy: Base LLMs, Self-Correction, Self-Correction + Our Cross-DPO.
### Detailed Analysis or ### Content Details
- **Llama3.1-8B-Instruct**: The baseline accuracy is 51.9%, and after self-correction, it increases to 55.1%. The accuracy with self-correction and cross-DPO is 55.4%.
- **DeepSeek-Math-7B**: The baseline accuracy is 46.8%, and after self-correction, it decreases to 43.2%. The accuracy with self-correction and cross-DPO is 43.5%.
- **Qwen2.5-Math-7B**: The baseline accuracy is 55.1%, and after self-correction, it increases to 57.3%. The accuracy with self-correction and cross-DPO is 57.6%.
- **GPT-40**: The baseline accuracy is 73.4%, and after self-correction, it increases to 75.7%. The accuracy with self-correction and cross-DPO is 76.0%.
- **Claude-3.5-Sonnet**: The baseline accuracy is 67.7%, and after self-correction, it increases to 70.1%. The accuracy with self-correction and cross-DPO is 70.4%.
- **Gemini-1.5-pro**: The baseline accuracy is 70.2%, and after self-correction, it increases to 72.5%. The accuracy with self-correction and cross-DPO is 72.8%.
- **SuperCorrect-Qwen-7B**: The baseline accuracy is 75.4%, and after self-correction, it increases to 77.6%. The accuracy with self-correction and cross-DPO is 78.0%.
### Key Observations
- The language models with self-correction show a significant improvement in accuracy compared to the baseline.
- The language models with self-correction and cross-DPO show the highest accuracy, indicating the effectiveness of the cross-DPO method.
- There is a noticeable increase in accuracy for all models after applying self-correction, with the highest increase observed in the SuperCorrect-Qwen-7B model.
### Interpretation
The data suggests that self-correction techniques can significantly improve the accuracy of language models on the MATH dataset. The cross-DPO method appears to be particularly effective, as it leads to the highest accuracy across all models. This improvement is crucial for applications that require high accuracy, such as educational tools and scientific research. The results also highlight the potential of self-correction methods in enhancing the performance of language models, which can have a positive impact on various fields that rely on accurate language processing.