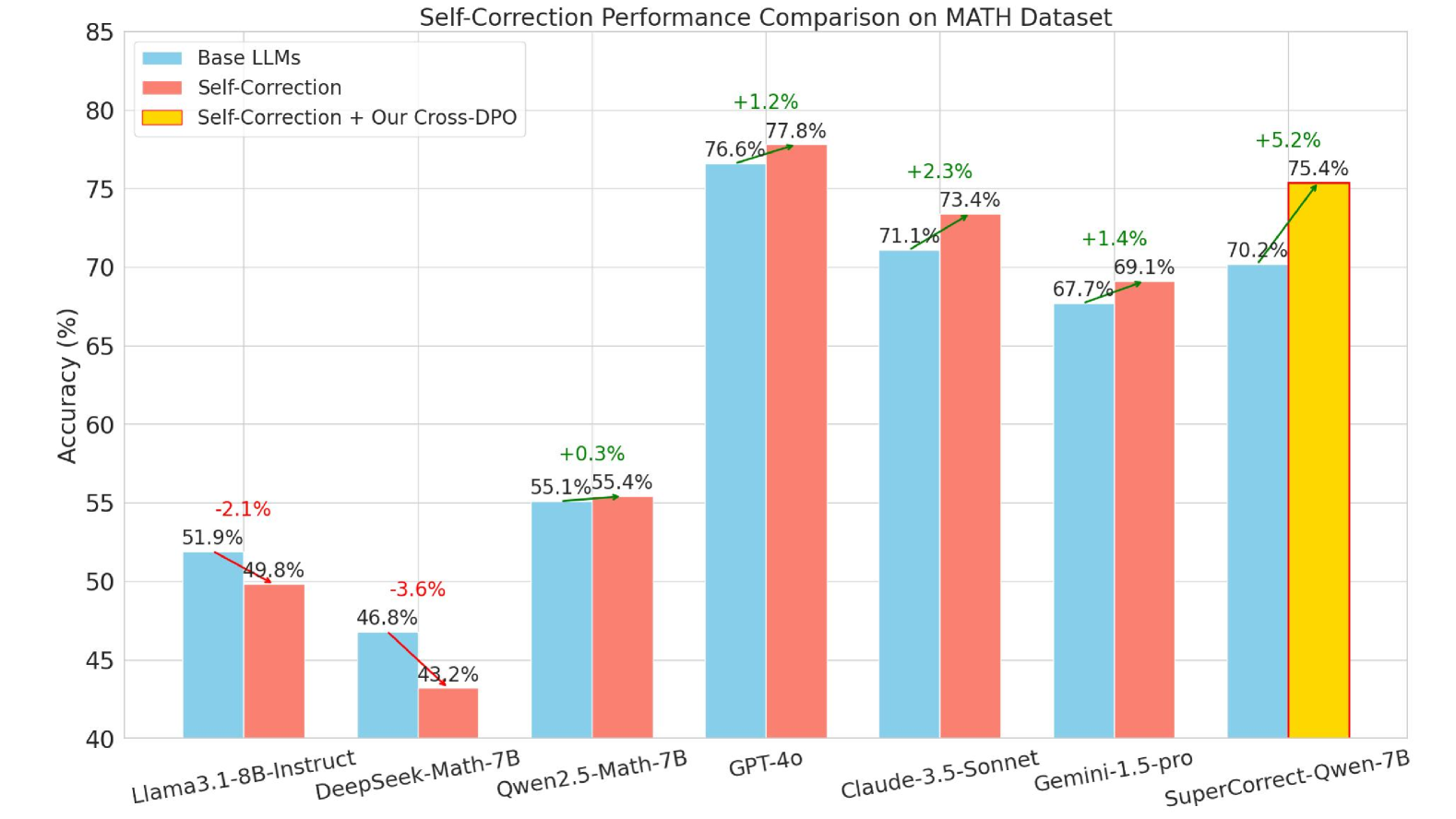
## Bar Chart: Self-Correction Performance Comparison on MATH Dataset
### Overview
The image is a bar chart comparing the performance (accuracy in percentage) of different Large Language Models (LLMs) on the MATH dataset. The chart compares the performance of "Base LLMs", "Self-Correction", and "Self-Correction + Our Cross-DPO" techniques across various models.
### Components/Axes
* **Title:** Self-Correction Performance Comparison on MATH Dataset
* **Y-axis:** Accuracy (%), with a scale from 40 to 85 in increments of 5.
* **X-axis:** LLM Models: Llama3.1-8B-Instruct, DeepSeek-Math-7B, Qwen2.5-Math-7B, GPT-4o, Claude-3.5-Sonnet, Gemini-1.5-pro, SuperCorrect-Qwen-7B
* **Legend:** Located at the top-left corner:
* Light Blue: Base LLMs
* Salmon: Self-Correction
* Yellow: Self-Correction + Our Cross-DPO
### Detailed Analysis
The chart presents accuracy percentages for each model under different conditions. The values are as follows:
* **Llama3.1-8B-Instruct:**
* Base LLMs (Light Blue): 51.9%
* Self-Correction (Salmon): 49.8%
* Difference: -2.1%
* **DeepSeek-Math-7B:**
* Base LLMs (Light Blue): 46.8%
* Self-Correction (Salmon): 43.2%
* Difference: -3.6%
* **Qwen2.5-Math-7B:**
* Base LLMs (Light Blue): 55.1%
* Self-Correction (Salmon): 55.4%
* Difference: +0.3%
* **GPT-4o:**
* Base LLMs (Light Blue): 76.6%
* Self-Correction (Salmon): 77.8%
* Difference: +1.2%
* **Claude-3.5-Sonnet:**
* Base LLMs (Light Blue): 71.1%
* Self-Correction (Salmon): 73.4%
* Difference: +2.3%
* **Gemini-1.5-pro:**
* Base LLMs (Light Blue): 67.7%
* Self-Correction (Salmon): 69.1%
* Difference: +1.4%
* **SuperCorrect-Qwen-7B:**
* Base LLMs (Light Blue): 70.2%
* Self-Correction + Our Cross-DPO (Yellow): 75.4%
* Difference: +5.2%
### Key Observations
* For Llama3.1-8B-Instruct and DeepSeek-Math-7B, self-correction *decreases* the accuracy.
* For Qwen2.5-Math-7B, GPT-4o, Claude-3.5-Sonnet, and Gemini-1.5-pro, self-correction *increases* the accuracy.
* SuperCorrect-Qwen-7B with "Self-Correction + Our Cross-DPO" shows the highest accuracy among the models tested.
### Interpretation
The chart indicates that the effectiveness of self-correction varies across different LLMs. For some models, it improves performance on the MATH dataset, while for others, it degrades performance. The "Self-Correction + Our Cross-DPO" technique appears to be particularly effective for the SuperCorrect-Qwen-7B model, resulting in a significant performance boost. This suggests that the benefits of self-correction are model-dependent and can be further enhanced by specific training techniques like Cross-DPO.