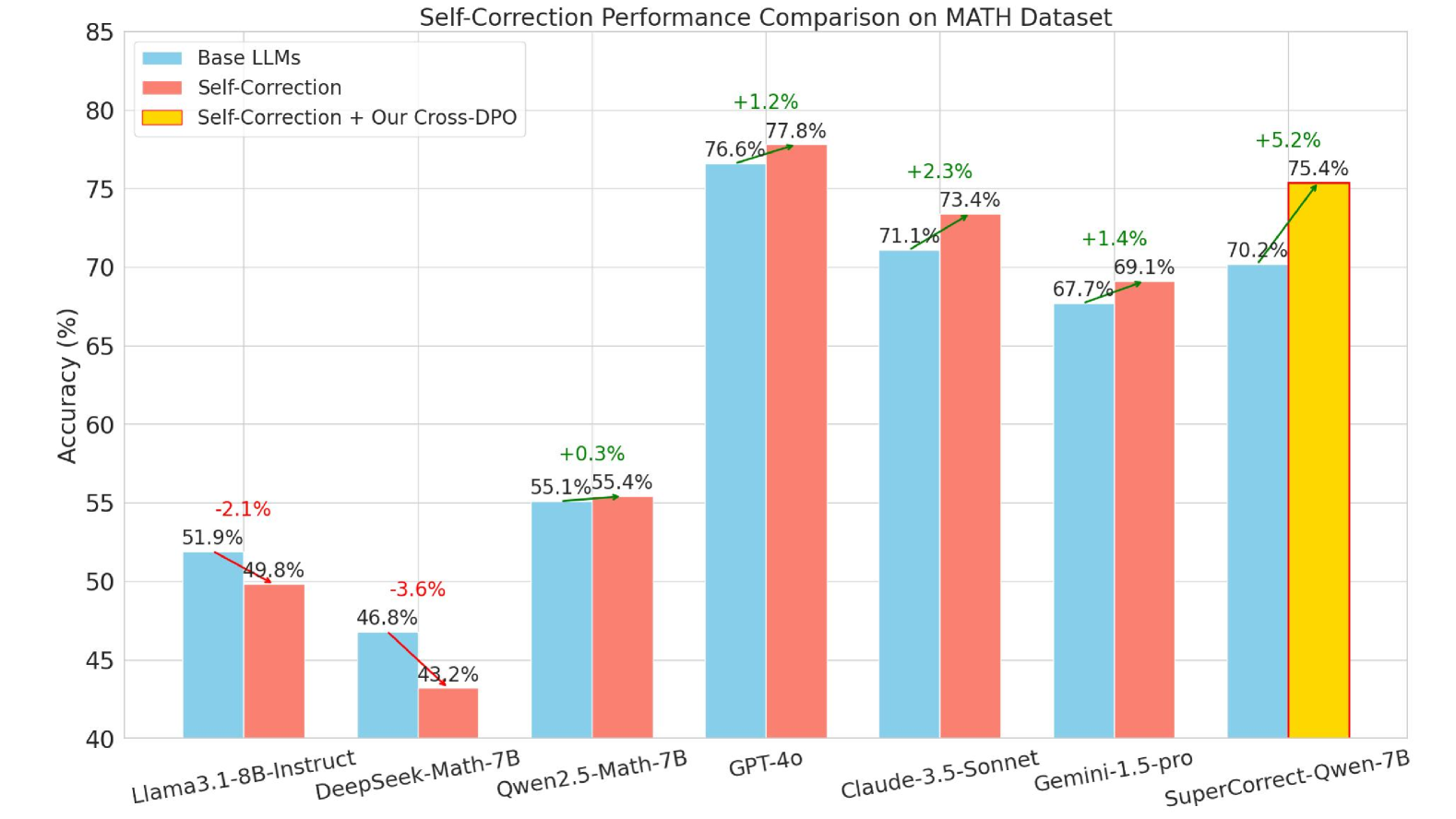
## Bar Chart: Self-Correction Performance Comparison on MATH Dataset
### Overview
This bar chart compares the accuracy of several Large Language Models (LLMs) on the MATH dataset, evaluating performance with three different approaches: Base LLMs, Self-Correction, and Self-Correction combined with Our Cross-DPO. Accuracy is measured in percentage (%).
### Components/Axes
* **X-axis:** LLM Names - Llama-3.8B-Instruct, DeepSeek-Math-7B, Qwen2.5-Math-7B, GPT-4, Claude-3.5-Sonnet, Gemini-1.5-pro, SuperCorrect-Qwen-7B.
* **Y-axis:** Accuracy (%) - Scale ranges from 40% to 85%.
* **Legend:**
* Blue: Base LLMs
* Red: Self-Correction
* Orange: Self-Correction + Our Cross-DPO
* **Title:** "Self-Correction Performance Comparison on MATH Dataset"
### Detailed Analysis
The chart consists of grouped bar plots for each LLM, representing the accuracy achieved under each of the three conditions. Each LLM has three bars next to each other, one for each condition. Percentage change values are displayed above the bars for the Self-Correction and Self-Correction + Our Cross-DPO conditions, relative to the Base LLM performance.
Here's a breakdown of the data points:
* **Llama-3.8B-Instruct:**
* Base LLMs: Approximately 51.9%
* Self-Correction: Approximately 49.8% (-2.1% change)
* Self-Correction + Our Cross-DPO: Approximately 43.2% (-3.6% change)
* **DeepSeek-Math-7B:**
* Base LLMs: Approximately 46.8%
* Self-Correction: Approximately 43.2% (-3.6% change)
* **Qwen2.5-Math-7B:**
* Base LLMs: Approximately 55.1%
* Self-Correction: Approximately 55.4% (+0.3% change)
* **GPT-4:**
* Base LLMs: Approximately 73.4%
* Self-Correction: Approximately 76.6% (+1.2% change)
* **Claude-3.5-Sonnet:**
* Base LLMs: Approximately 71.1%
* Self-Correction: Approximately 73.4% (+2.3% change)
* **Gemini-1.5-pro:**
* Base LLMs: Approximately 67.7%
* Self-Correction: Approximately 70.2% (+1.4% change)
* **SuperCorrect-Qwen-7B:**
* Base LLMs: Approximately 75.4%
* Self-Correction + Our Cross-DPO: Approximately 75.4% (+5.2% change)
### Key Observations
* For Llama-3.8B-Instruct and DeepSeek-Math-7B, self-correction *decreases* accuracy compared to the base LLM.
* Qwen2.5-Math-7B shows a slight improvement with self-correction.
* GPT-4, Claude-3.5-Sonnet, and Gemini-1.5-pro all show improvements with self-correction.
* SuperCorrect-Qwen-7B shows the largest improvement with the combined self-correction and Cross-DPO approach.
* The largest performance difference between base LLM and the combined approach is observed with SuperCorrect-Qwen-7B.
### Interpretation
The data suggests that the effectiveness of self-correction techniques varies significantly depending on the underlying LLM. For some models (Llama-3.8B-Instruct, DeepSeek-Math-7B), self-correction appears to be detrimental, potentially due to the models' inherent limitations or the specific implementation of the self-correction process. However, for more capable models (GPT-4, Claude-3.5-Sonnet, Gemini-1.5-pro), self-correction improves accuracy. The substantial improvement observed with SuperCorrect-Qwen-7B, when combined with Cross-DPO, indicates that a well-tuned self-correction process, leveraging techniques like Cross-DPO, can significantly enhance performance on the MATH dataset. The negative changes for Llama and DeepSeek suggest that these models may benefit from a different self-correction strategy or further pre-training. The MATH dataset is a challenging benchmark for mathematical reasoning, and the results highlight the importance of model capacity and the quality of the self-correction mechanism.