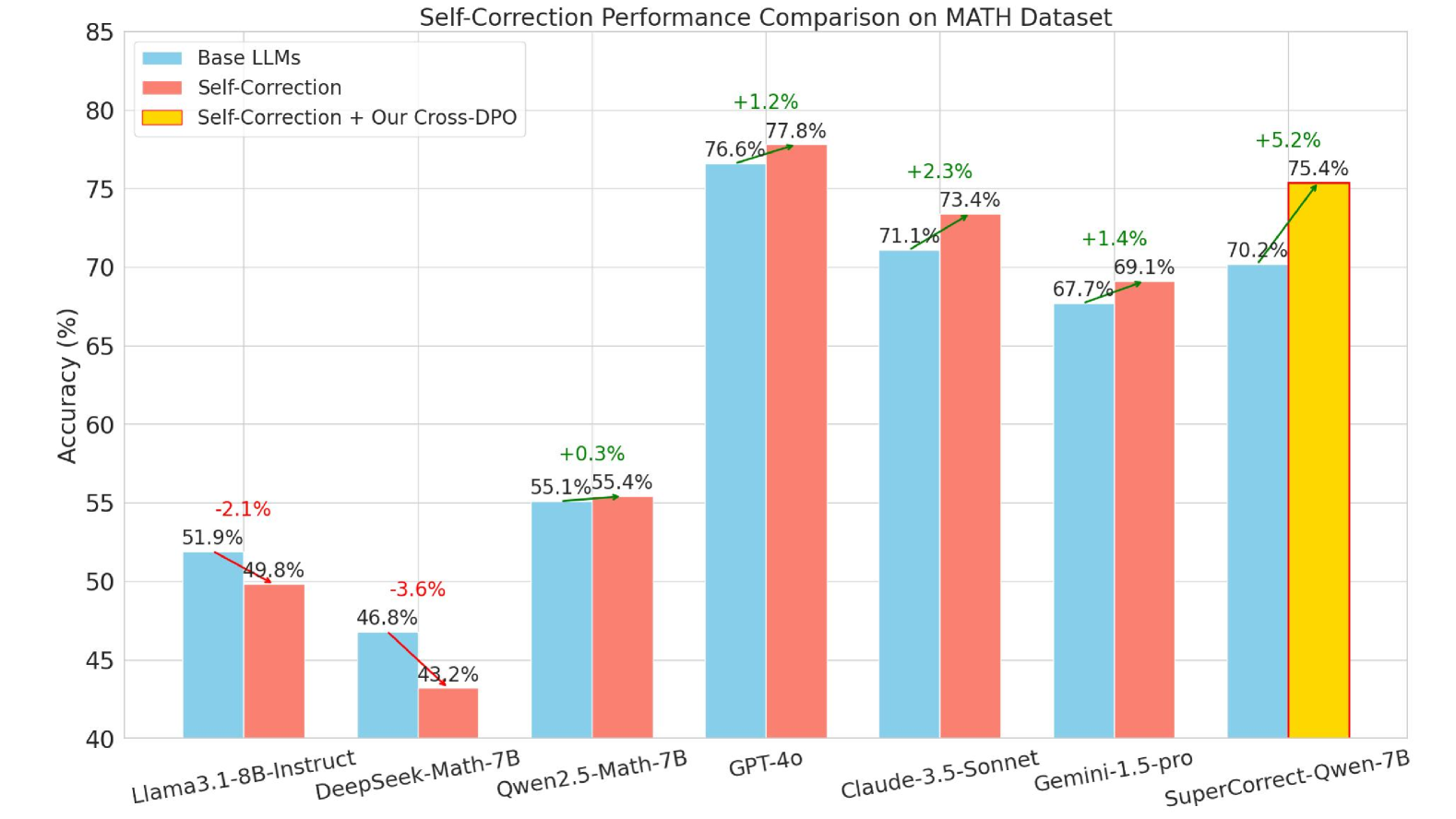
## Bar Chart: Self-Correction Performance Comparison on MATH Dataset
### Overview
This is a grouped bar chart comparing the accuracy (in percentage) of various Large Language Models (LLMs) on the MATH dataset under three different conditions: the base model, the model with self-correction, and the model with self-correction enhanced by a method called "Cross-DPO." The chart visualizes the performance change introduced by self-correction and the additional impact of the Cross-DPO technique.
### Components/Axes
* **Chart Title:** "Self-Correction Performance Comparison on MATH Dataset"
* **Y-Axis:** Labeled "Accuracy (%)". The scale runs from 40 to 85, with major gridlines at intervals of 5%.
* **X-Axis:** Lists seven different LLM models. From left to right:
1. Llama3.1-8B-Instruct
2. DeepSeek-Math-7B
3. Qwen2.5-Math-7B
4. GPT-4o
5. Claude-3.5-Sonnet
6. Gemini-1.5-pro
7. SuperCorrect-Qwen-7B
* **Legend:** Positioned in the top-left corner of the chart area.
* **Blue Bar:** "Base LLMs"
* **Red Bar:** "Self-Correction"
* **Yellow Bar:** "Self-Correction + Our Cross-DPO"
* **Data Annotations:** Each bar has its exact accuracy percentage written above it. For the "Self-Correction" (red) and "Self-Correction + Our Cross-DPO" (yellow) bars, a green or red arrow and a percentage value indicate the change from the corresponding "Base LLMs" (blue) bar.
### Detailed Analysis
The performance data for each model, extracted by matching bar colors to the legend, is as follows:
1. **Llama3.1-8B-Instruct**
* Base LLMs (Blue): 51.9%
* Self-Correction (Red): 49.8%
* **Trend:** The red bar is shorter than the blue bar. The annotation shows a **-2.1%** change (red arrow), indicating self-correction decreased accuracy.
2. **DeepSeek-Math-7B**
* Base LLMs (Blue): 46.8%
* Self-Correction (Red): 43.2%
* **Trend:** The red bar is shorter than the blue bar. The annotation shows a **-3.6%** change (red arrow), indicating self-correction decreased accuracy.
3. **Qwen2.5-Math-7B**
* Base LLMs (Blue): 55.1%
* Self-Correction (Red): 55.4%
* **Trend:** The red bar is marginally taller than the blue bar. The annotation shows a **+0.3%** change (green arrow), indicating a very slight improvement from self-correction.
4. **GPT-4o**
* Base LLMs (Blue): 76.6%
* Self-Correction (Red): 77.8%
* **Trend:** The red bar is taller than the blue bar. The annotation shows a **+1.2%** change (green arrow), indicating self-correction improved accuracy.
5. **Claude-3.5-Sonnet**
* Base LLMs (Blue): 71.1%
* Self-Correction (Red): 73.4%
* **Trend:** The red bar is taller than the blue bar. The annotation shows a **+2.3%** change (green arrow), indicating self-correction improved accuracy.
6. **Gemini-1.5-pro**
* Base LLMs (Blue): 67.7%
* Self-Correction (Red): 69.1%
* **Trend:** The red bar is taller than the blue bar. The annotation shows a **+1.4%** change (green arrow), indicating self-correction improved accuracy.
7. **SuperCorrect-Qwen-7B**
* Base LLMs (Blue): 70.2%
* Self-Correction + Our Cross-DPO (Yellow): 75.4%
* **Trend:** This model group only shows the Base and the enhanced condition. The yellow bar is significantly taller than the blue bar. The annotation shows a **+5.2%** change (green arrow), indicating the Cross-DPO method provided a substantial boost over the base model.
### Key Observations
* **Variable Impact of Self-Correction:** The effect of standard self-correction (red bars) is inconsistent. It leads to a performance **decrease** for Llama3.1-8B-Instruct (-2.1%) and DeepSeek-Math-7B (-3.6%), a negligible increase for Qwen2.5-Math-7B (+0.3%), and a moderate increase for the larger models GPT-4o, Claude-3.5-Sonnet, and Gemini-1.5-pro.
* **Strong Performance of Larger Models:** The base accuracy (blue bars) is generally higher for the proprietary models (GPT-4o, Claude-3.5-Sonnet, Gemini-1.5-pro) compared to the smaller, open-source models listed on the left.
* **Significant Gain from Cross-DPO:** The "Self-Correction + Our Cross-DPO" condition (yellow bar) is only shown for the SuperCorrect-Qwen-7B model, where it yields the largest single improvement on the chart (+5.2%).
* **Highest Overall Accuracy:** GPT-4o with self-correction achieves the highest displayed accuracy at 77.8%.
### Interpretation
The data suggests that the efficacy of self-correction as a technique for improving mathematical reasoning in LLMs is highly model-dependent. It is not a universal enhancer and can even be detrimental to some models (like Llama3.1-8B-Instruct and DeepSeek-Math-7B in this test). The positive gains observed in larger, more capable base models (GPT-4o, Claude, Gemini) might indicate that self-correction requires a certain threshold of foundational reasoning ability to be beneficial.
The most notable result is the performance of "SuperCorrect-Qwen-7B" with the added "Cross-DPO" method. The +5.2% jump is the largest improvement shown, implying that this specific technique (Cross-DPO) may be a more effective or targeted way to leverage self-correction for performance gains on the MATH dataset compared to standard self-correction alone. The chart serves as evidence that simply applying self-correction is insufficient; the method of implementation (like Cross-DPO) and the base model's characteristics are critical factors for success.