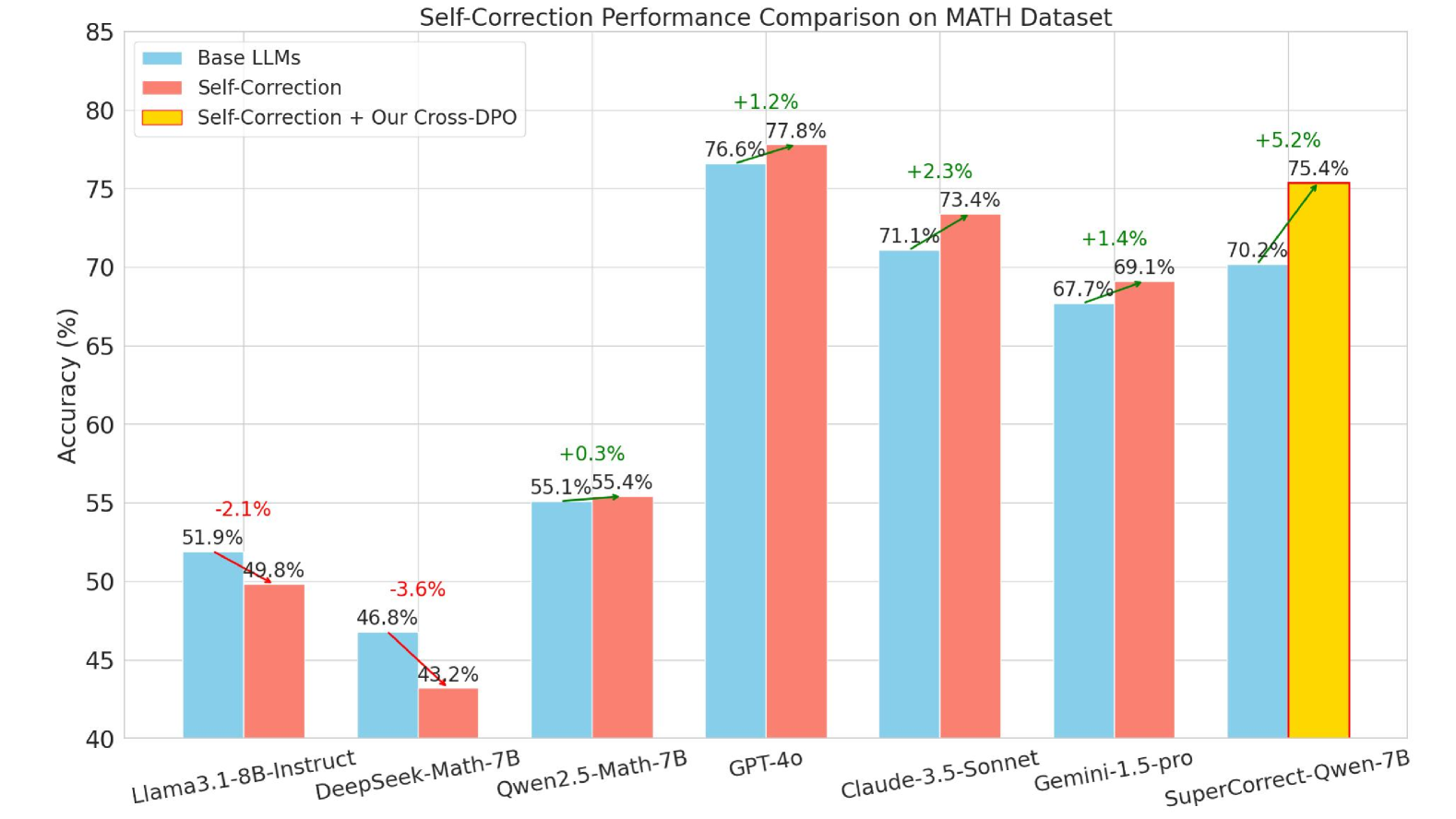
# Self-Correction Performance Comparison on MATH Dataset
## Chart Structure
- **Title**: "Self-Correction Performance Comparison on MATH Dataset"
- **X-Axis**: Model names (categorical)
- **Y-Axis**: Accuracy (%) [40% to 85%]
- **Legend**: Located in top-left corner
- Blue: Base LLMs
- Red: Self-Correction
- Yellow: Self-Correction + Our Cross-DPO
## Data Series
1. **Base LLMs** (Blue)
2. **Self-Correction** (Red)
3. **Self-Correction + Our Cross-DPO** (Yellow)
## Key Data Points & Annotations
| Model | Base LLMs (%) | Self-Correction (%) | Self-Correction + Cross-DPO (%) | Change vs Base LLMs |
|------------------------|---------------|---------------------|----------------------------------|---------------------|
| Llama3.1-8B-Instruct | 51.9 | 49.8 | - | -2.1% |
| DeepSeek-Math-7B | 46.8 | 43.2 | - | -3.6% |
| Qwen2.5-Math-7B | 55.1 | 55.4 | - | +0.3% |
| GPT-4o | 76.6 | 77.8 | - | +1.2% |
| Claude-3.5-Sonnet | 71.1 | 73.4 | - | +2.3% |
| Gemini-1.5-pro | 67.7 | 69.1 | - | +1.4% |
| SuperCorrect-Qwen-7B | 70.2 | 75.4 | 75.4 | +5.2% |
## Spatial Grounding
- **Legend Position**: Top-left corner
- **Bar Colors**:
- Blue bars: Base LLMs
- Red bars: Self-Correction
- Yellow bar: Self-Correction + Cross-DPO (only for SuperCorrect-Qwen-7B)
## Trend Verification
1. **Llama3.1-8B-Instruct**: Base LLMs (51.9%) → Self-Correction (49.8%) [↓]
2. **DeepSeek-Math-7B**: Base LLMs (46.8%) → Self-Correction (43.2%) [↓]
3. **Qwen2.5-Math-7B**: Base LLMs (55.1%) → Self-Correction (55.4%) [↑]
4. **GPT-4o**: Base LLMs (76.6%) → Self-Correction (77.8%) [↑]
5. **Claude-3.5-Sonnet**: Base LLMs (71.1%) → Self-Correction (73.4%) [↑]
6. **Gemini-1.5-pro**: Base LLMs (67.7%) → Self-Correction (69.1%) [↑]
7. **SuperCorrect-Qwen-7B**:
- Base LLMs (70.2%) → Self-Correction (75.4%) [↑]
- Self-Correction + Cross-DPO (75.4%) [→]
## Critical Observations
1. **Performance Gains**:
- Self-Correction improves accuracy in 5/7 models
- Cross-DPO further enhances performance in SuperCorrect-Qwen-7B (+5.2%)
2. **Largest Improvement**: SuperCorrect-Qwen-7B shows the most significant gain (+5.2%)
3. **Performance Loss**:
- Llama3.1-8B-Instruct and DeepSeek-Math-7B show declines (-2.1% and -3.6%)
## Language Notes
- All text is in English
- No non-English content detected