\n
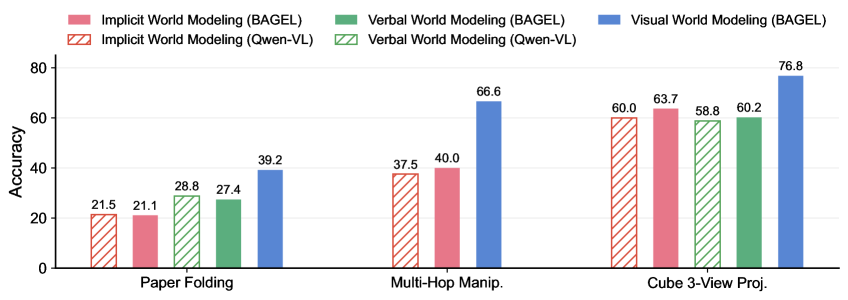
## Bar Chart: Accuracy Comparison of World Modeling Techniques
### Overview
This bar chart compares the accuracy of different world modeling techniques – Implicit, Verbal, and Visual – using two different models, BAGEL and Qwen-VL, across three tasks: Paper Folding, Multi-Hop Manipulation, and Cube 3-View Projection. Accuracy is measured on the y-axis, while the x-axis represents the different tasks. Each task has six bars representing the accuracy of each modeling technique and model combination.
### Components/Axes
* **X-axis:** Tasks - "Paper Folding", "Multi-Hop Manip.", "Cube 3-View Proj."
* **Y-axis:** Accuracy (Scale from 0 to 80, increments of 10)
* **Legend:**
* Red: Implicit World Modeling (BAGEL)
* Light Red (Hatched): Implicit World Modeling (Qwen-VL)
* Green: Verbal World Modeling (BAGEL)
* Light Green (Hatched): Verbal World Modeling (Qwen-VL)
* Blue: Visual World Modeling (BAGEL)
* Light Blue (Hatched): Visual World Modeling (Qwen-VL)
### Detailed Analysis
The chart consists of three groups of bars, one for each task. Within each group, there are six bars representing the accuracy of each model/technique combination.
**Paper Folding:**
* Implicit World Modeling (BAGEL): Approximately 21.5% accuracy.
* Implicit World Modeling (Qwen-VL): Approximately 21.1% accuracy.
* Verbal World Modeling (BAGEL): Approximately 28.8% accuracy.
* Verbal World Modeling (Qwen-VL): Approximately 27.4% accuracy.
* Visual World Modeling (BAGEL): Approximately 39.2% accuracy.
* Visual World Modeling (Qwen-VL): No bar is present.
**Multi-Hop Manip.:**
* Implicit World Modeling (BAGEL): Approximately 37.5% accuracy.
* Implicit World Modeling (Qwen-VL): Approximately 40.0% accuracy.
* Verbal World Modeling (BAGEL): Approximately 66.6% accuracy.
* Verbal World Modeling (Qwen-VL): No bar is present.
* Visual World Modeling (BAGEL): No bar is present.
* Visual World Modeling (Qwen-VL): No bar is present.
**Cube 3-View Proj.:**
* Implicit World Modeling (BAGEL): Approximately 60.0% accuracy.
* Implicit World Modeling (Qwen-VL): Approximately 63.7% accuracy.
* Verbal World Modeling (BAGEL): Approximately 58.8% accuracy.
* Verbal World Modeling (Qwen-VL): Approximately 60.2% accuracy.
* Visual World Modeling (BAGEL): Approximately 76.8% accuracy.
* Visual World Modeling (Qwen-VL): No bar is present.
### Key Observations
* Visual World Modeling (BAGEL) consistently achieves the highest accuracy across the Paper Folding and Cube 3-View Projection tasks.
* Verbal World Modeling (BAGEL) achieves the highest accuracy on the Multi-Hop Manipulation task.
* Qwen-VL generally performs similarly to or slightly worse than BAGEL for Implicit World Modeling.
* There are missing bars for Qwen-VL in the Verbal and Visual World Modeling categories for the Multi-Hop Manipulation and Cube 3-View Projection tasks. This suggests that these combinations were not evaluated or the results were not significant enough to display.
* The accuracy values for Implicit World Modeling are relatively low compared to Verbal and Visual World Modeling.
### Interpretation
The data suggests that the choice of world modeling technique significantly impacts accuracy, with Visual World Modeling (BAGEL) and Verbal World Modeling (BAGEL) generally outperforming Implicit World Modeling. The best technique depends on the task; Verbal World Modeling excels at Multi-Hop Manipulation, while Visual World Modeling is superior for Paper Folding and Cube 3-View Projection. The consistent performance of BAGEL compared to Qwen-VL for Implicit World Modeling indicates that BAGEL may be a more effective model for this technique. The missing data points for Qwen-VL in certain categories warrant further investigation to understand why these combinations were not evaluated or yielded insignificant results. The overall trend shows that more complex tasks (like Cube 3-View Projection) benefit from more sophisticated modeling techniques (like Visual World Modeling), as evidenced by the higher accuracy scores.