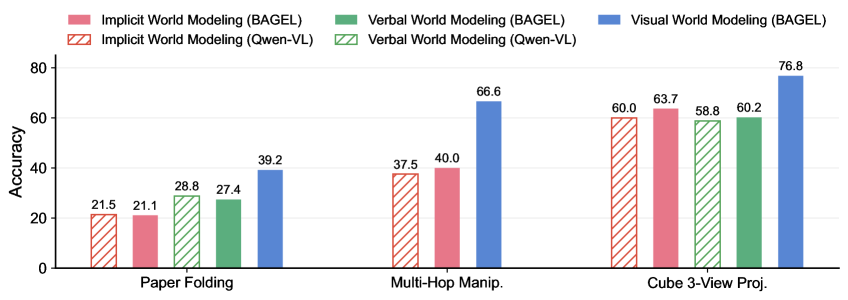
## Grouped Bar Chart: Accuracy Comparison of World Modeling Approaches
### Overview
The image displays a grouped bar chart comparing the accuracy of three world modeling approaches (Implicit, Verbal, and Visual) across two different models (BAGEL and Qwen-VL) on three distinct spatial reasoning tasks. The chart is designed to evaluate and contrast model performance.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **X-Axis (Categorical):** Lists three tasks. From left to right:
1. `Paper Folding`
2. `Multi-Hop Manip.` (Abbreviation for "Multi-Hop Manipulation")
3. `Cube 3-View Proj.` (Abbreviation for "Cube 3-View Projection")
* **Y-Axis (Numerical):** Labeled `Accuracy`. The scale runs from 0 to 80, with major tick marks at intervals of 20 (0, 20, 40, 60, 80).
* **Legend (Top Center):** Positioned above the chart area. It defines six data series using a combination of color and fill pattern:
* **Pink Solid Bar:** `Implicit World Modeling (BAGEL)`
* **Pink Hatched Bar (Diagonal Lines):** `Implicit World Modeling (Qwen-VL)`
* **Green Solid Bar:** `Verbal World Modeling (BAGEL)`
* **Green Hatched Bar (Diagonal Lines):** `Verbal World Modeling (Qwen-VL)`
* **Blue Solid Bar:** `Visual World Modeling (BAGEL)`
* **Note:** There is no corresponding `Visual World Modeling (Qwen-VL)` series represented in the chart.
### Detailed Analysis
The chart presents accuracy scores for each model-method combination across the three tasks. Values are read from the top of each bar.
**1. Paper Folding Task (Leftmost Group):**
* **Implicit (Qwen-VL, Pink Hatched):** ~21.5
* **Implicit (BAGEL, Pink Solid):** ~21.1
* **Verbal (Qwen-VL, Green Hatched):** ~28.8
* **Verbal (BAGEL, Green Solid):** ~27.4
* **Visual (BAGEL, Blue Solid):** ~39.2
* **Trend:** Visual modeling (BAGEL) significantly outperforms both Implicit and Verbal approaches. Verbal modeling scores slightly higher than Implicit for both models.
**2. Multi-Hop Manipulation Task (Center Group):**
* **Implicit (Qwen-VL, Pink Hatched):** ~37.5
* **Implicit (BAGEL, Pink Solid):** ~40.0
* **Verbal (Qwen-VL, Green Hatched):** ~40.0
* **Verbal (BAGEL, Green Solid):** ~66.6
* **Visual (BAGEL, Blue Solid):** ~66.6
* **Trend:** A substantial performance jump is observed for BAGEL's Verbal and Visual models, which tie for the highest score. Qwen-VL's Implicit and Verbal models show moderate improvement from the previous task.
**3. Cube 3-View Projection Task (Rightmost Group):**
* **Implicit (Qwen-VL, Pink Hatched):** ~60.0
* **Implicit (BAGEL, Pink Solid):** ~63.7
* **Verbal (Qwen-VL, Green Hatched):** ~58.8
* **Verbal (BAGEL, Green Solid):** ~60.2
* **Visual (BAGEL, Blue Solid):** ~76.8
* **Trend:** All models achieve their highest scores on this task. BAGEL's Visual model again demonstrates a clear lead. The performance gap between Implicit and Verbal approaches narrows considerably for both models.
### Key Observations
1. **Consistent Superiority of Visual Modeling:** The `Visual World Modeling (BAGEL)` approach (blue solid bar) is the top performer in every task, with its lead being most pronounced in the "Paper Folding" and "Cube 3-View Projection" tasks.
2. **Task Difficulty Gradient:** Accuracy for all methods generally increases from left to right across the tasks, suggesting "Paper Folding" is the most challenging and "Cube 3-View Projection" is the least challenging for these models.
3. **Model Comparison (BAGEL vs. Qwen-VL):** For Implicit and Verbal modeling, the BAGEL and Qwen-VL variants often perform within a few points of each other. However, BAGEL shows a dramatic advantage in Verbal modeling on the "Multi-Hop Manipulation" task (66.6 vs. 40.0).
4. **Missing Data Series:** The chart includes no data for `Visual World Modeling (Qwen-VL)`, indicating this combination was either not tested or not applicable.
### Interpretation
This chart provides a comparative analysis of how different AI modeling paradigms handle spatial reasoning. The data suggests that **explicitly visual representations (Visual World Modeling) confer a significant advantage** for tasks involving mental manipulation of objects and spatial relationships, as seen in the consistent lead of the blue bars.
The progression of scores implies the tasks are ordered by increasing complexity or by better alignment with the models' training. The "Cube 3-View Projection" task, which likely involves interpreting 2D representations of a 3D object, appears to be the most solvable, possibly reflecting strong priors in the models' training data about geometric projections.
The near parity between BAGEL and Qwen-VL in most Implicit/Verbal comparisons, contrasted with BAGEL's outsized success in Visual modeling and one specific Verbal task, hints at architectural or training differences that make BAGEL particularly adept at leveraging visual and complex verbal reasoning for spatial problems. The absence of a Qwen-VL visual model is a critical gap in the comparison, leaving open whether its visual capabilities would close the performance gap.