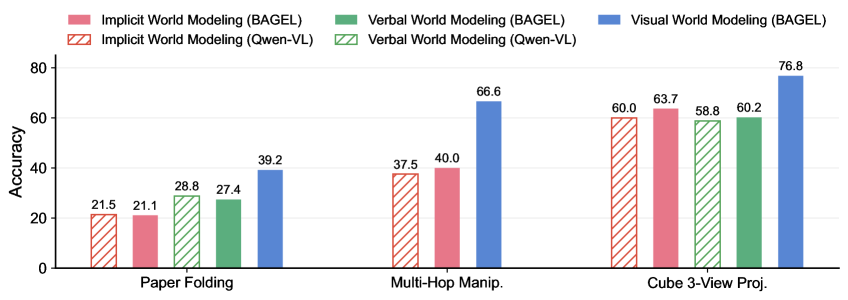
## Bar Chart: Accuracy of World Modeling Approaches Across Tasks
### Overview
The chart compares the accuracy of three world modeling approaches—Implicit, Verbal, and Visual—across three tasks: Paper Folding, Multi-Hop Manipulation, and Cube 3-View Projection. Each approach is evaluated using two models (BAGEL and Qwen-VL) for Implicit and Verbal, while Visual is only evaluated with BAGEL. The data highlights performance differences between models and approaches.
### Components/Axes
- **X-axis**: Tasks (Paper Folding, Multi-Hop Manip., Cube 3-View Proj.)
- **Y-axis**: Accuracy (0–80%)
- **Legend**:
- **Implicit World Modeling (BAGEL)**: Solid red
- **Implicit World Modeling (Qwen-VL)**: Red with diagonal stripes
- **Verbal World Modeling (BAGEL)**: Solid green
- **Verbal World Modeling (Qwen-VL)**: Green with diagonal stripes
- **Visual World Modeling (BAGEL)**: Solid blue
### Detailed Analysis
- **Paper Folding**:
- Implicit BAGEL: 21.5% (solid red)
- Implicit Qwen-VL: 21.1% (red striped)
- Verbal BAGEL: 28.8% (solid green)
- Verbal Qwen-VL: 27.4% (green striped)
- Visual BAGEL: 39.2% (solid blue)
- **Multi-Hop Manip.**:
- Implicit BAGEL: 37.5% (solid red)
- Implicit Qwen-VL: 40.0% (red striped)
- Visual BAGEL: 66.6% (solid blue)
- **Cube 3-View Proj.**:
- Implicit BAGEL: 60.0% (solid red)
- Implicit Qwen-VL: 63.7% (red striped)
- Verbal BAGEL: 58.8% (solid green)
- Verbal Qwen-VL: 60.2% (green striped)
- Visual BAGEL: 76.8% (solid blue)
### Key Observations
1. **Visual World Modeling (BAGEL)** consistently achieves the highest accuracy across all tasks, with the largest margin in Cube 3-View Proj. (76.8%).
2. **Implicit approaches** (BAGEL and Qwen-VL) show lower performance, with Qwen-VL slightly outperforming BAGEL in Multi-Hop Manip. (40.0% vs. 37.5%).
3. **Verbal approaches** (BAGEL and Qwen-VL) perform better than Implicit but lag behind Visual. In Cube 3-View Proj., Verbal Qwen-VL (60.2%) surpasses Verbal BAGEL (58.8%).
4. **Qwen-VL** outperforms BAGEL in Implicit and Verbal categories for Multi-Hop and Cube tasks, suggesting model-specific advantages.
### Interpretation
The data demonstrates that **Visual World Modeling (BAGEL)** is the most effective approach, likely due to its ability to integrate spatial and contextual information critical for tasks like Cube 3-View Projection. The **Implicit** and **Verbal** approaches show diminishing returns, with Qwen-VL occasionally outperforming BAGEL in the same category, indicating that model architecture (Qwen-VL) may enhance performance in specific scenarios. The stark difference in Cube 3-View Proj. (76.8% vs. ~60% for others) underscores the importance of visual reasoning in complex spatial tasks. This suggests that future work should prioritize Visual World Modeling for applications requiring high accuracy in spatial reasoning.