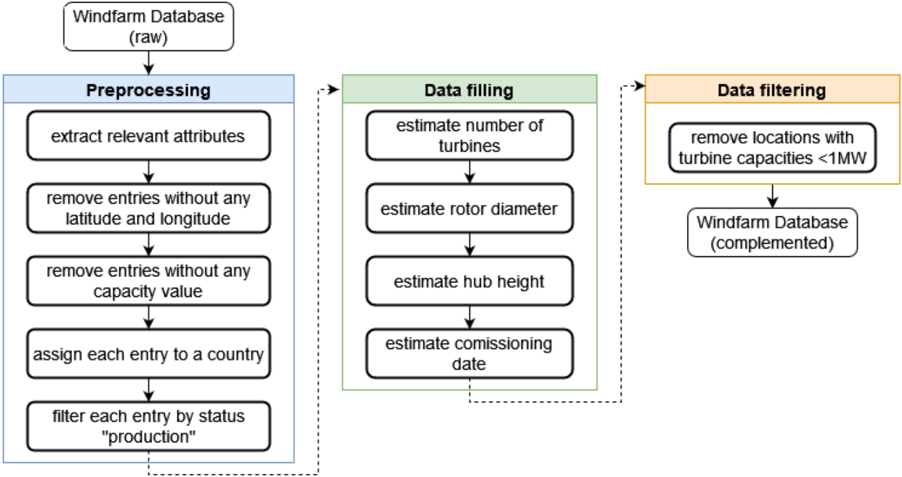
## Flowchart: Windfarm Database Processing Pipeline
### Overview
The image displays a three-stage flowchart illustrating a data processing pipeline for a windfarm database. The process transforms a raw database into a complemented, filtered database through sequential steps of preprocessing, data filling, and data filtering. The flow is indicated by solid arrows within each stage and dashed arrows connecting the stages.
### Components/Axes
The diagram is organized into three main colored rectangular containers, arranged horizontally from left to right:
1. **Preprocessing** (Light blue container, left)
2. **Data filling** (Light green container, center)
3. **Data filtering** (Light orange container, right)
**Input:** A rounded rectangle at the top-left labeled "Windfarm Database (raw)".
**Output:** A rounded rectangle at the bottom-right labeled "Windfarm Database (complemented)".
### Detailed Analysis
The pipeline consists of the following sequential steps:
**1. Preprocessing Stage (Blue Container)**
This stage contains five sequential processing steps, each in a white rounded rectangle, connected by downward-pointing solid arrows:
* Step 1: `extract relevant attributes`
* Step 2: `remove entries without any latitude and longitude`
* Step 3: `remove entries without any capacity value`
* Step 4: `assign each entry to a country`
* Step 5: `filter each entry by status "production"`
A dashed arrow exits the bottom of the Preprocessing container and points to the top of the Data filling container.
**2. Data Filling Stage (Green Container)**
This stage contains four sequential estimation steps, each in a white rounded rectangle, connected by downward-pointing solid arrows:
* Step 1: `estimate number of turbines`
* Step 2: `estimate rotor diameter`
* Step 3: `estimate hub height`
* Step 4: `estimate comissioning date` (Note: "comissioning" appears to be a misspelling of "commissioning").
A dashed arrow exits the bottom of the Data filling container and points to the top of the Data filtering container.
**3. Data Filtering Stage (Orange Container)**
This stage contains one processing step in a white rounded rectangle:
* Step: `remove locations with turbine capacities <1MW`
A solid arrow points downward from this step to the final output.
### Key Observations
* **Logical Flow:** The pipeline follows a clear, logical sequence: clean the raw data (Preprocessing), impute missing values (Data filling), and apply a final business rule filter (Data filtering).
* **Data Quality Focus:** The Preprocessing stage is heavily focused on data quality, removing entries lacking essential geospatial (lat/long) and technical (capacity) data, and filtering for operational ("production") assets.
* **Estimation Phase:** The Data filling stage is entirely dedicated to estimating missing technical specifications (turbine count, rotor diameter, hub height, commissioning date), suggesting the raw database is incomplete.
* **Final Filter:** The single step in Data filtering applies a capacity threshold (<1MW), which likely removes small-scale or experimental installations to focus the final dataset on utility-scale wind farms.
* **Visual Coding:** The use of distinct background colors (blue, green, orange) effectively segments the three major phases of the pipeline.
### Interpretation
This flowchart details a systematic data engineering process designed to create a clean, complete, and analysis-ready dataset of operational, utility-scale wind farms from a raw, likely messy, source database.
The process reveals several underlying assumptions and priorities:
1. **Geospatial and Capacity Data are Foundational:** Entries missing location or capacity are considered unusable and are discarded early.
2. **Country-Level Analysis is Important:** Assigning a country is a key preprocessing step, indicating the final dataset is intended for national or regional analysis.
3. **"Production" Status is Key:** The pipeline focuses exclusively on operational assets, excluding those in planning, construction, or decommissioning phases.
4. **Missing Data is Common but Estimable:** The dedicated "Data filling" stage implies that key technical parameters are frequently absent in the raw data but can be reasonably estimated, likely using industry averages or models based on other available attributes.
5. **Scale Matters:** The final filter removing sub-1MW locations defines the scope of the resulting database to commercial-scale wind power generation.
In essence, this pipeline transforms a raw inventory into a curated dataset suitable for technical, economic, or spatial analysis of the established wind energy sector, with a clear emphasis on data completeness and operational relevance.