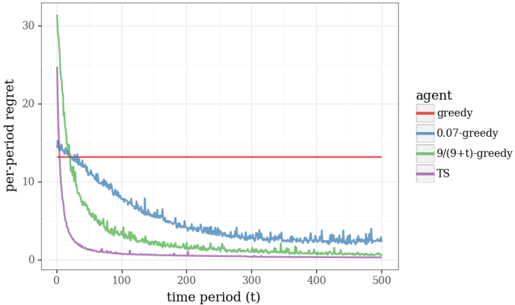
## Line Chart: Per-Period Regret vs. Time Period for Different Agents
### Overview
The image is a line chart comparing the per-period regret of four different agents (greedy, 0.07-greedy, 9/(9+t)-greedy, and TS) over time. The x-axis represents the time period (t), ranging from 0 to 500. The y-axis represents the per-period regret, ranging from 0 to 30. The chart illustrates how the regret changes for each agent as the time period increases.
### Components/Axes
* **X-axis:**
* Label: "time period (t)"
* Scale: 0 to 500, with markers at 0, 100, 200, 300, 400, and 500.
* **Y-axis:**
* Label: "per-period regret"
* Scale: 0 to 30, with markers at 0, 10, 20, and 30.
* **Legend (Top-Right):**
* "agent"
* Red: "greedy"
* Blue: "0.07-greedy"
* Green: "9/(9+t)-greedy"
* Purple: "TS"
### Detailed Analysis
* **Greedy (Red):** The red line representing the "greedy" agent remains constant at a per-period regret of approximately 13.5.
* **0.07-greedy (Blue):** The blue line representing the "0.07-greedy" agent starts at a regret of approximately 15 and decreases over time, stabilizing around a regret of approximately 3 after 300 time periods.
* **9/(9+t)-greedy (Green):** The green line representing the "9/(9+t)-greedy" agent starts at a regret of approximately 31 and decreases rapidly, stabilizing around a regret of approximately 2 after 200 time periods.
* **TS (Purple):** The purple line representing the "TS" agent starts at a regret of approximately 24 and decreases rapidly, stabilizing around a regret of approximately 0.5 after 100 time periods.
### Key Observations
* The "greedy" agent has a constant regret over time.
* The "0.07-greedy", "9/(9+t)-greedy", and "TS" agents all show decreasing regret over time, with "TS" converging to a low regret value most quickly.
* The "TS" agent achieves the lowest regret value among all agents.
### Interpretation
The chart demonstrates the performance of different exploration strategies in a reinforcement learning setting, as measured by per-period regret. The "greedy" agent, which does not explore, maintains a constant regret. The other agents, which incorporate exploration, show decreasing regret as they learn the optimal policy. The "TS" agent, which uses Thompson Sampling, appears to be the most effective exploration strategy, as it converges to a low regret value most quickly. The "9/(9+t)-greedy" agent also performs well, converging to a low regret value, but not as quickly as the "TS" agent. The "0.07-greedy" agent converges slower than the "9/(9+t)-greedy" and "TS" agents.