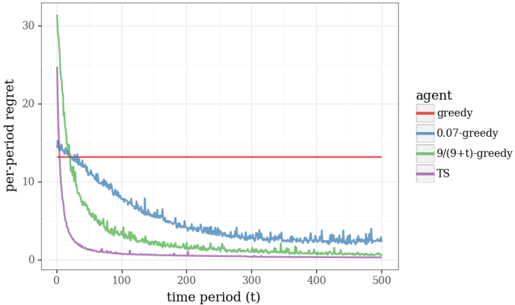
## Line Graph: Per-Period Regret Over Time for Different Agents
### Overview
The graph illustrates the convergence of per-period regret over time for five distinct agents in a reinforcement learning or optimization context. The y-axis represents "per-period regret" (0–30), and the x-axis represents "time period (t)" (0–500). A horizontal red line at ~14 regret serves as a baseline for comparison.
### Components/Axes
- **Y-Axis**: "per-period regret" (linear scale, 0–30).
- **X-Axis**: "time period (t)" (linear scale, 0–500).
- **Legend**: Located on the right, with five entries:
- **Red**: "greedy" (constant regret line).
- **Blue**: "0.07-greedy" (line with moderate decline).
- **Green**: "9/(9+t)-greedy" (line with steep initial decline).
- **Purple**: "TS" (line with fastest initial decline).
- **Horizontal Red Line**: Labeled "greedy" (baseline at ~14 regret).
### Detailed Analysis
1. **Greedy (Red Line)**:
- Constant regret at ~14 across all time periods.
- No convergence; remains static.
2. **0.07-Greedy (Blue Line)**:
- Starts at ~20 regret at t=0.
- Gradual decline to ~3 regret by t=500.
- Slight fluctuations but overall stable after t=200.
3. **9/(9+t)-Greedy (Green Line)**:
- Starts at ~30 regret at t=0.
- Sharp decline to ~1 regret by t=50.
- Stabilizes near 0.5–1 regret by t=500.
4. **TS (Purple Line)**:
- Starts at ~25 regret at t=0.
- Rapid decline to ~2 regret by t=50.
- Fluctuates slightly but stabilizes near 1–2 regret by t=500.
5. **Baseline (Horizontal Red Line)**:
- Fixed at ~14 regret, representing the "greedy" agent's performance.
### Key Observations
- **Fastest Convergence**: The "TS" agent (purple) achieves the lowest regret (~1–2) by t=50, outperforming all others.
- **Time-Dependent Adaptation**: The "9/(9+t)-greedy" (green) agent shows strong initial improvement but plateaus at ~1 regret, slower than TS.
- **Moderate Adaptation**: The "0.07-greedy" (blue) agent converges slowly, reaching ~3 regret by t=500.
- **Static Baseline**: The "greedy" agent (red) remains unchanged, serving as a reference for non-adaptive performance.
### Interpretation
The data demonstrates that adaptive algorithms (TS and 9/(9+t)-greedy) significantly outperform static strategies (greedy and 0.07-greedy) in minimizing regret over time. The TS agent achieves the fastest and most efficient convergence, suggesting it is the optimal choice for dynamic environments. The 9/(9+t)-greedy agent, while effective, converges more slowly than TS, indicating a trade-off between adaptability and computational complexity. The "greedy" agent’s stagnation highlights the limitations of non-adaptive strategies in evolving scenarios. This analysis underscores the importance of incorporating time-dependent adjustments or exploration mechanisms (e.g., TS) to improve long-term performance in reinforcement learning tasks.