\n
## Bar Charts: Training Time Comparison
### Overview
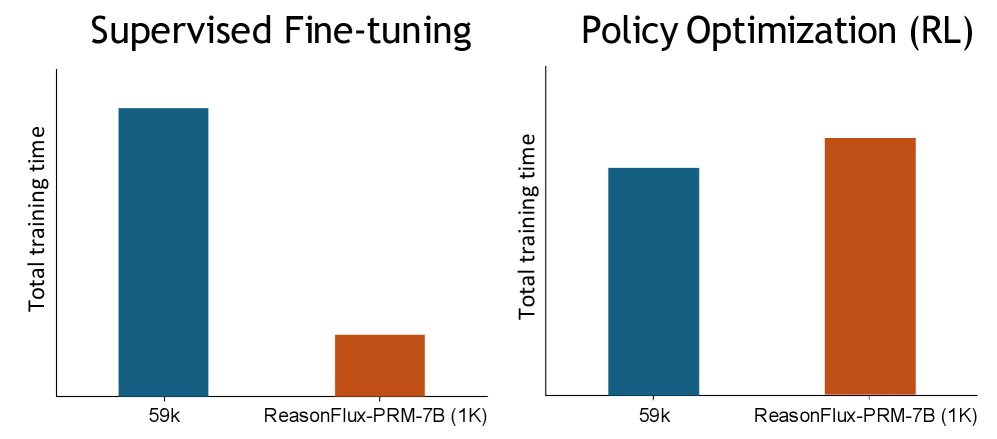
The image presents two bar charts comparing the total training time for different models under two training paradigms: Supervised Fine-tuning and Policy Optimization (Reinforcement Learning - RL). Each chart compares the training time for "59k" and "ReasonFlux-PRM-7B (1K)" models.
### Components/Axes
* **X-axis:** Model Name ("59k", "ReasonFlux-PRM-7B (1K)")
* **Y-axis:** Total training time (unspecified units, but assumed to be consistent across both charts)
* **Chart 1 Title:** "Supervised Fine-tuning" (top-left)
* **Chart 2 Title:** "Policy Optimization (RL)" (top-right)
* **Bar Colors:**
* "59k": Dark Blue
* "ReasonFlux-PRM-7B (1K)": Orange-Red
### Detailed Analysis or Content Details
**Chart 1: Supervised Fine-tuning**
* **59k:** The dark blue bar reaches approximately 1.75 on the Y-axis.
* **ReasonFlux-PRM-7B (1K):** The orange-red bar reaches approximately 0.3 on the Y-axis.
* **Trend:** The "59k" model takes significantly longer to train than the "ReasonFlux-PRM-7B (1K)" model.
**Chart 2: Policy Optimization (RL)**
* **59k:** The dark blue bar reaches approximately 1.2 on the Y-axis.
* **ReasonFlux-PRM-7B (1K):** The orange-red bar reaches approximately 1.8 on the Y-axis.
* **Trend:** The "ReasonFlux-PRM-7B (1K)" model takes significantly longer to train than the "59k" model.
### Key Observations
* The relative training times of the models are reversed between the two training paradigms.
* "59k" is faster in Supervised Fine-tuning, but slower in Policy Optimization (RL).
* "ReasonFlux-PRM-7B (1K)" is slower in Supervised Fine-tuning, but faster in Policy Optimization (RL).
* The difference in training time is more pronounced in the Supervised Fine-tuning chart.
### Interpretation
The data suggests that the optimal model choice depends heavily on the training paradigm used. The "59k" model appears to be more efficient for Supervised Fine-tuning, while the "ReasonFlux-PRM-7B (1K)" model is more efficient for Policy Optimization (RL). This could be due to differences in model architecture, learning rates, or other hyperparameters that are better suited to each training method. The reversal in training time indicates a complex interaction between the model and the training process. Further investigation would be needed to understand the underlying reasons for this behavior. The magnitude of the difference in training time is larger for Supervised Fine-tuning, suggesting that the choice of training paradigm has a more significant impact on the "59k" model's performance.