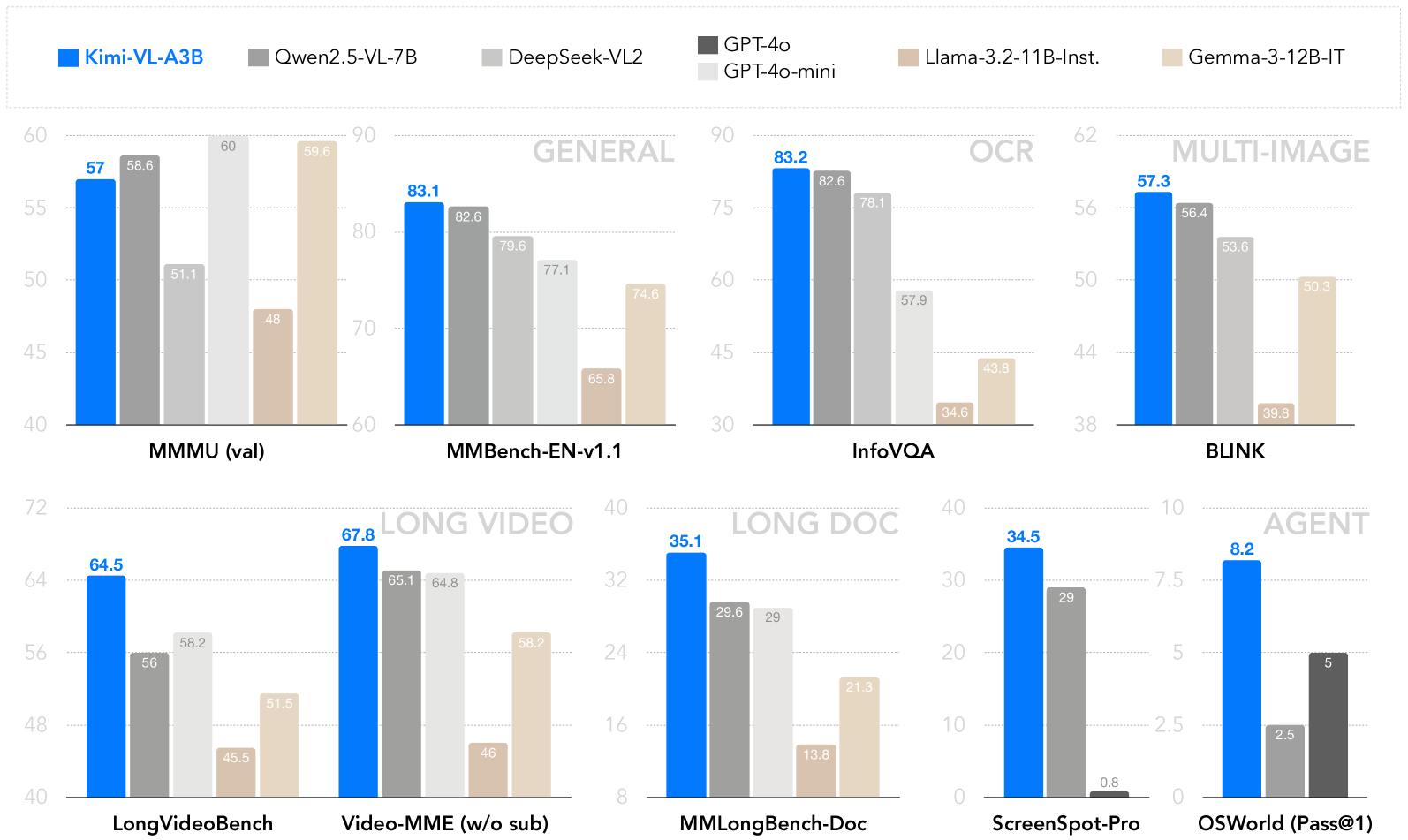
## Bar Chart: Model Performance Across Benchmarks
### Overview
The image is a grouped bar chart comparing the performance of seven AI models across nine benchmarks. Models include Kimi-VL-A3B (blue), Qwen2.5-VL-7B (dark gray), DeepSeek-VL2 (light gray), GPT-4o (black), GPT-4o-mini (white), Llama-3-2-11B-Instruct (tan), and Gemma-3-12B-IT (light tan). Benchmarks are categorized into "General," "OCR," "Multi-Image," "Long Video," "Long Doc," and "Agent" tasks. Scores are represented as percentages on the y-axis (0–90 range).
---
### Components/Axes
- **X-Axis**: Benchmarks (e.g., MMMU (val), MMBench-EN-v1.1, InfoVQA, BLINK, LongVideoBench, Video-MME (w/o sub), MMLongBench-Doc, ScreenSpot-Pro, OSWorld (Pass@1)).
- **Y-Axis**: Performance scores (0–90, labeled "Score").
- **Legend**: Top-left corner, mapping colors to models.
- **Bars**: Grouped by benchmark, with individual bars for each model. Numerical values are displayed atop bars.
---
### Detailed Analysis
#### General Benchmarks
- **MMMU (val)**:
- Kimi-VL-A3B: 57.0
- Qwen2.5-VL-7B: 58.6
- DeepSeek-VL2: 51.1
- GPT-4o: 60.0
- GPT-4o-mini: 48.0
- Llama-3-2-11B-Instruct: 59.6
- Gemma-3-12B-IT: 48.0
- **MMBench-EN-v1.1**:
- Kimi-VL-A3B: 83.1
- Qwen2.5-VL-7B: 82.6
- DeepSeek-VL2: 79.6
- GPT-4o: 77.1
- GPT-4o-mini: 65.8
- Llama-3-2-11B-Instruct: 74.6
- Gemma-3-12B-IT: 65.8
#### OCR Benchmarks
- **InfoVQA**:
- Kimi-VL-A3B: 83.2
- Qwen2.5-VL-7B: 82.6
- DeepSeek-VL2: 78.1
- GPT-4o: 57.9
- GPT-4o-mini: 43.8
- Llama-3-2-11B-Instruct: 34.6
- Gemma-3-12B-IT: 43.8
#### Multi-Image Benchmarks
- **BLINK**:
- Kimi-VL-A3B: 57.3
- Qwen2.5-VL-7B: 56.4
- DeepSeek-VL2: 53.6
- GPT-4o: 39.8
- GPT-4o-mini: 50.3
- Llama-3-2-11B-Instruct: 50.3
- Gemma-3-12B-IT: 50.3
#### Long Video Benchmarks
- **LongVideoBench**:
- Kimi-VL-A3B: 64.5
- Qwen2.5-VL-7B: 56.0
- DeepSeek-VL2: 58.2
- GPT-4o: 45.5
- GPT-4o-mini: 51.5
- Llama-3-2-11B-Instruct: 46.0
- Gemma-3-12B-IT: 58.2
- **Video-MME (w/o sub)**:
- Kimi-VL-A3B: 67.8
- Qwen2.5-VL-7B: 65.1
- DeepSeek-VL2: 64.8
- GPT-4o: 46.0
- GPT-4o-mini: 46.0
- Llama-3-2-11B-Instruct: 58.2
- Gemma-3-12B-IT: 46.0
#### Long Doc Benchmarks
- **MMLongBench-Doc**:
- Kimi-VL-A3B: 35.1
- Qwen2.5-VL-7B: 29.6
- DeepSeek-VL2: 29.0
- GPT-4o: 13.8
- GPT-4o-mini: 21.3
- Llama-3-2-11B-Instruct: 21.3
- Gemma-3-12B-IT: 21.3
#### Agent Benchmarks
- **ScreenSpot-Pro**:
- Kimi-VL-A3B: 34.5
- Qwen2.5-VL-7B: 29.0
- DeepSeek-VL2: 0.8
- GPT-4o: 0.8
- GPT-4o-mini: 0.8
- Llama-3-2-11B-Instruct: 0.8
- Gemma-3-12B-IT: 0.8
- **OSWorld (Pass@1)**:
- Kimi-VL-A3B: 8.2
- Qwen2.5-VL-7B: 2.5
- DeepSeek-VL2: 5.0
- GPT-4o: 5.0
- GPT-4o-mini: 5.0
- Llama-3-2-11B-Instruct: 5.0
- Gemma-3-12B-IT: 5.0
---
### Key Observations
1. **Kimi-VL-A3B** consistently outperforms other models in most benchmarks, particularly in **MMBench-EN-v1.1** (83.1) and **Video-MME** (67.8).
2. **GPT-4o** and **GPT-4o-mini** show strong performance in **General** and **OCR** tasks but lag in **Long Doc** and **Agent** benchmarks.
3. **Llama-3-2-11B-Instruct** and **Gemma-3-12B-IT** perform comparably in **Multi-Image** tasks but underperform in **Long Doc** and **Agent** tasks.
4. **DeepSeek-VL2** excels in **LongVideoBench** (58.2) but struggles in **Agent** tasks (0.8).
5. **Qwen2.5-VL-7B** shows balanced performance across most benchmarks but lags in **Agent** tasks.
---
### Interpretation
The chart highlights **Kimi-VL-A3B** as the most versatile model, excelling across diverse tasks. **GPT-4o** and **GPT-4o-mini** dominate **General** and **OCR** tasks but underperform in **Long Doc** and **Agent** benchmarks, suggesting limitations in handling extended text or interactive tasks. **Llama-3-2-11B-Instruct** and **Gemma-3-12B-IT** show niche strengths in **Multi-Image** tasks but lack consistency elsewhere. The stark drop in performance for **Agent** tasks (e.g., **ScreenSpot-Pro**: 0.8 for most models) indicates a critical gap in real-world application readiness for many models. This data underscores the importance of model selection based on specific use cases, with **Kimi-VL-A3B** emerging as a strong candidate for broad applicability.