TECHNICAL ASSET FINGERPRINT
2e71d3fa569fe5499ea760b9
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
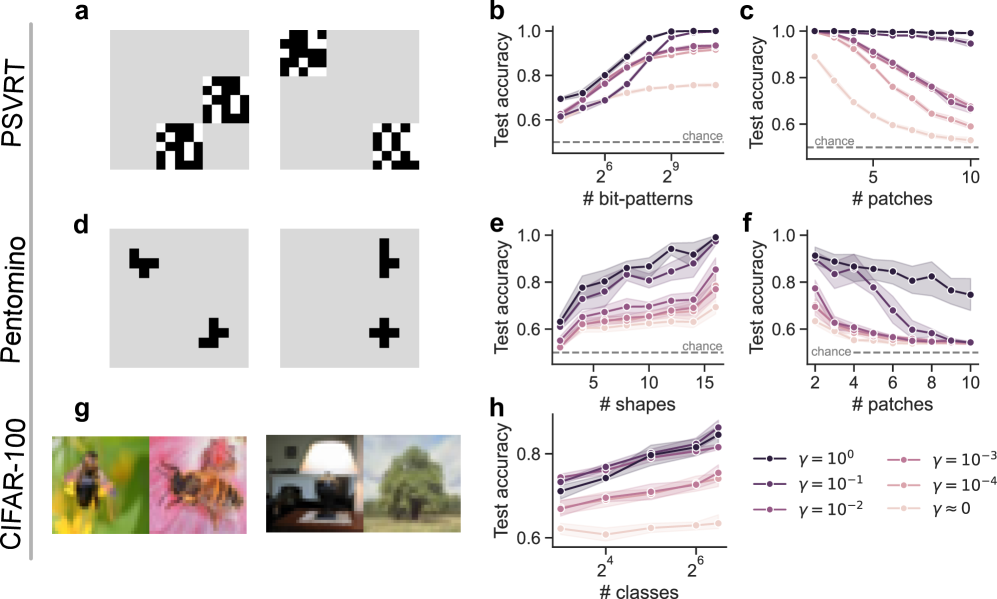
## Charts/Graphs: Performance Evaluation of Visual Representation Learning
### Overview
The image presents a series of charts evaluating the performance of a visual representation learning model across three different datasets: PSVRT, Pentomino, and CIFAR-100. The performance metric is "Test accuracy," plotted against varying parameters of each dataset (bit-patterns, patches, shapes, classes). Each chart includes a horizontal line representing "chance" level accuracy. Multiple lines within each chart represent different values of a parameter γ (gamma).
### Components/Axes
The image is organized into a 3x3 grid of subplots.
* **Datasets:** PSVRT (a, b, c), Pentomino (d, e, f), CIFAR-100 (g, h).
* **X-axes:**
* (b) # bit-patterns (scale: 2<sup>6</sup> to 2<sup>9</sup>)
* (c) # patches (scale: 5 to 10)
* (e) # shapes (scale: 5 to 15)
* (f) # patches (scale: 2 to 10)
* (h) # classes (scale: 2<sup>4</sup> to 2<sup>6</sup>)
* **Y-axes:** All charts share a "Test accuracy" scale ranging from 0.6 to 1.0.
* **Horizontal Line:** A dashed horizontal line labeled "chance" is present in all charts, positioned around y = 0.5.
* **Legend (bottom-right of h):**
* γ = 10<sup>0</sup> (solid line, dark grey)
* γ = 10<sup>-1</sup> (solid line, grey)
* γ = 10<sup>-2</sup> (solid line, light grey)
* γ = 10<sup>-3</sup> (dashed line, dark grey)
* γ = 10<sup>-4</sup> (dashed line, grey)
* γ ≈ 0 (dashed line, light grey)
* **Images (g):** Four example images from the CIFAR-100 dataset are displayed.
### Detailed Analysis or Content Details
**PSVRT (a, b, c):**
* **(b) Test accuracy vs. # bit-patterns:** All lines show an increasing trend in test accuracy as the number of bit-patterns increases. The γ = 10<sup>0</sup> line (dark grey) consistently achieves the highest accuracy, approaching 0.95 at 2<sup>9</sup> bit-patterns. The γ ≈ 0 line (light grey dashed) starts near the chance level and shows a modest increase, remaining below 0.7.
* At 2<sup>6</sup> bit-patterns: Accuracy values are approximately: γ = 10<sup>0</sup>: 0.75, γ = 10<sup>-1</sup>: 0.72, γ = 10<sup>-2</sup>: 0.68, γ = 10<sup>-3</sup>: 0.65, γ = 10<sup>-4</sup>: 0.63, γ ≈ 0: 0.58.
* At 2<sup>9</sup> bit-patterns: Accuracy values are approximately: γ = 10<sup>0</sup>: 0.95, γ = 10<sup>-1</sup>: 0.92, γ = 10<sup>-2</sup>: 0.88, γ = 10<sup>-3</sup>: 0.85, γ = 10<sup>-4</sup>: 0.82, γ ≈ 0: 0.75.
* **(c) Test accuracy vs. # patches:** The γ = 10<sup>0</sup> line (dark grey) starts high and decreases slightly as the number of patches increases, remaining above 0.85. The γ ≈ 0 line (light grey dashed) shows a slight increase, but remains below 0.7.
* At 5 patches: Accuracy values are approximately: γ = 10<sup>0</sup>: 0.90, γ = 10<sup>-1</sup>: 0.85, γ = 10<sup>-2</sup>: 0.80, γ = 10<sup>-3</sup>: 0.75, γ = 10<sup>-4</sup>: 0.70, γ ≈ 0: 0.65.
* At 10 patches: Accuracy values are approximately: γ = 10<sup>0</sup>: 0.85, γ = 10<sup>-1</sup>: 0.80, γ = 10<sup>-2</sup>: 0.75, γ = 10<sup>-3</sup>: 0.70, γ = 10<sup>-4</sup>: 0.65, γ ≈ 0: 0.60.
**Pentomino (d, e, f):**
* **(e) Test accuracy vs. # shapes:** All lines show an increasing trend in test accuracy as the number of shapes increases. The γ = 10<sup>0</sup> line (dark grey) consistently achieves the highest accuracy, approaching 1.0 at 15 shapes. The γ ≈ 0 line (light grey dashed) shows a modest increase, remaining below 0.7.
* At 5 shapes: Accuracy values are approximately: γ = 10<sup>0</sup>: 0.85, γ = 10<sup>-1</sup>: 0.80, γ = 10<sup>-2</sup>: 0.75, γ = 10<sup>-3</sup>: 0.70, γ = 10<sup>-4</sup>: 0.65, γ ≈ 0: 0.60.
* At 15 shapes: Accuracy values are approximately: γ = 10<sup>0</sup>: 0.98, γ = 10<sup>-1</sup>: 0.95, γ = 10<sup>-2</sup>: 0.90, γ = 10<sup>-3</sup>: 0.85, γ = 10<sup>-4</sup>: 0.80, γ ≈ 0: 0.70.
* **(f) Test accuracy vs. # patches:** Similar to PSVRT (c), the γ = 10<sup>0</sup> line (dark grey) starts high and decreases slightly as the number of patches increases, remaining above 0.8. The γ ≈ 0 line (light grey dashed) shows a slight increase, but remains below 0.7.
**CIFAR-100 (g, h):**
* **(h) Test accuracy vs. # classes:** All lines show an increasing trend in test accuracy as the number of classes increases. The γ = 10<sup>0</sup> line (dark grey) consistently achieves the highest accuracy, approaching 0.95 at 2<sup>6</sup> classes. The γ ≈ 0 line (light grey dashed) shows a modest increase, remaining below 0.7.
* At 2<sup>4</sup> classes: Accuracy values are approximately: γ = 10<sup>0</sup>: 0.75, γ = 10<sup>-1</sup>: 0.72, γ = 10<sup>-2</sup>: 0.68, γ = 10<sup>-3</sup>: 0.65, γ = 10<sup>-4</sup>: 0.63, γ ≈ 0: 0.58.
* At 2<sup>6</sup> classes: Accuracy values are approximately: γ = 10<sup>0</sup>: 0.95, γ = 10<sup>-1</sup>: 0.92, γ = 10<sup>-2</sup>: 0.88, γ = 10<sup>-3</sup>: 0.85, γ = 10<sup>-4</sup>: 0.82, γ ≈ 0: 0.75.
### Key Observations
* Higher values of γ generally lead to higher test accuracy across all datasets and parameters.
* The γ = 10<sup>0</sup> line consistently outperforms all other γ values.
* The "chance" level accuracy is consistently below the performance of all γ values, indicating that the model is learning something beyond random chance.
* In PSVRT (c) and Pentomino (f), increasing the number of patches beyond a certain point leads to a slight decrease in accuracy for higher γ values.
### Interpretation
The data suggests that the visual representation learning model is effective at learning representations from these datasets. The parameter γ appears to control the strength of some regularization or learning signal, with higher values leading to better performance. The slight decrease in accuracy with increasing patches in PSVRT (c) and Pentomino (f) might indicate that the model is overfitting to the specific patch configurations at higher numbers. The consistent improvement in accuracy with increasing bit-patterns, shapes, and classes suggests that the model benefits from more complex and diverse input data. The fact that all γ values outperform chance level indicates that the model is not simply memorizing the training data but is learning meaningful features. The consistent performance of γ = 10<sup>0</sup> suggests that this value represents an optimal balance between model complexity and generalization ability. The images in (g) demonstrate the diversity of the CIFAR-100 dataset, which likely contributes to the model's ability to learn robust representations.
DECODING INTELLIGENCE...