## Chart/Diagram Type: Multi-panel Visualization of Model Performance
### Overview
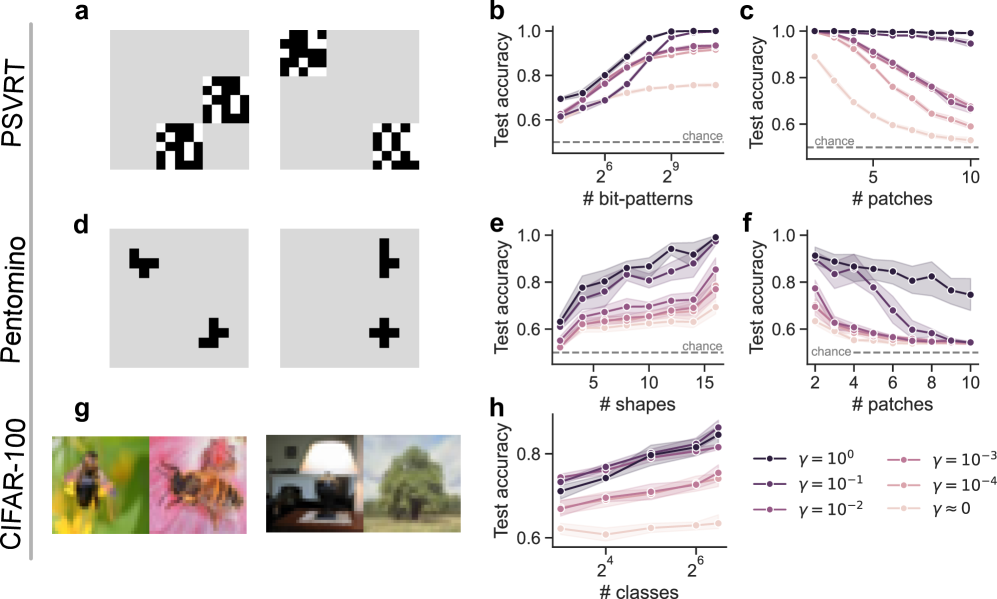
The image presents a multi-panel visualization comparing model performance across different datasets and configurations. It includes binary pattern examples (a-d), sample images (g), and five line graphs (b-f, h) showing test accuracy trends under varying parameters.
### Components/Axes
- **Left Panel Labels**:
- `PSVRT` (top-left)
- `Pentomino` (middle-left)
- `CIFAR-100` (bottom-left)
- **Graph Axes**:
- **Graph b**:
- X-axis: `# bit-patterns` (log scale: 2⁶ to 2⁹)
- Y-axis: `Test accuracy` (0.6–1.0)
- Legend: `γ = 10⁰` (dark purple), `γ = 10⁻¹` (medium purple), `γ = 10⁻²` (light purple), `γ = 10⁻³` (pink), `γ ≈ 0` (light pink)
- **Graph c**:
- X-axis: `# patches` (2 to 10)
- Y-axis: `Test accuracy` (0.6–1.0)
- Legend: Same γ values as graph b
- **Graph e**:
- X-axis: `# shapes` (2⁴ to 2⁶)
- Y-axis: `Test accuracy` (0.6–1.0)
- Legend: Same γ values
- **Graph f**:
- X-axis: `# patches` (2 to 10)
- Y-axis: `Test accuracy` (0.6–1.0)
- Legend: Same γ values
- **Graph h**:
- X-axis: `# classes` (2⁴ to 2⁶)
- Y-axis: `Test accuracy` (0.6–1.0)
- Legend: Same γ values
- **Legend Position**: Bottom-right of all graphs.
- **Shaded Regions**: Represent confidence intervals or variability (e.g., ±σ).
### Detailed Analysis
- **Graph b**:
- Accuracy increases with `# bit-patterns` for all γ values.
- γ = 10⁰ (dark purple) achieves highest accuracy (~0.95 at 2⁹ bit-patterns).
- γ ≈ 0 (light pink) plateaus near chance level (~0.6).
- **Graph c**:
- Accuracy decreases with `# patches` for all γ values.
- γ = 10⁰ (dark purple) retains ~0.8 accuracy at 10 patches.
- γ ≈ 0 (light pink) drops to ~0.55 at 10 patches.
- **Graph e**:
- Accuracy increases with `# shapes` for all γ values.
- γ = 10⁰ (dark purple) reaches ~0.9 at 2⁶ shapes.
- γ ≈ 0 (light pink) plateaus at ~0.65.
- **Graph f**:
- Accuracy decreases with `# patches` for all γ values.
- γ = 10⁰ (dark purple) retains ~0.85 at 10 patches.
- γ ≈ 0 (light pink) drops to ~0.5.
- **Graph h**:
- Accuracy increases with `# classes` for all γ values.
- γ = 10⁰ (dark purple) achieves ~0.95 at 2⁶ classes.
- γ ≈ 0 (light pink) plateaus at ~0.6.
### Key Observations
1. **γ Parameter Impact**: Higher γ values (e.g., 10⁰) consistently outperform lower γ values across all graphs.
2. **Dataset-Specific Trends**:
- PSVRT (graph b) and Pentomino (graph d) show sensitivity to bit-pattern complexity.
- CIFAR-100 (graph g) demonstrates robustness to class diversity.
3. **Overfitting Risk**: Lower γ values (e.g., 10⁻³, 10⁻⁴) exhibit sharper declines in accuracy with increased complexity (e.g., patches, classes).
4. **Shaded Regions**: Indicate variability, with γ = 10⁰ showing tighter confidence intervals.
### Interpretation
The data suggests that model performance is highly dependent on the regularization parameter γ and the complexity of the input data. Higher γ values (stronger regularization) mitigate overfitting, maintaining accuracy even as input complexity increases (e.g., more patches, classes). Conversely, lower γ values (weaker regularization) lead to overfitting, where accuracy degrades sharply with complexity. The shaded regions highlight that γ = 10⁰ provides the most stable performance across datasets, while γ ≈ 0 (no regularization) results in erratic behavior. This aligns with Peircean principles of abductive reasoning: the simplest explanation (γ = 10⁰) best accounts for the observed trends across diverse datasets.