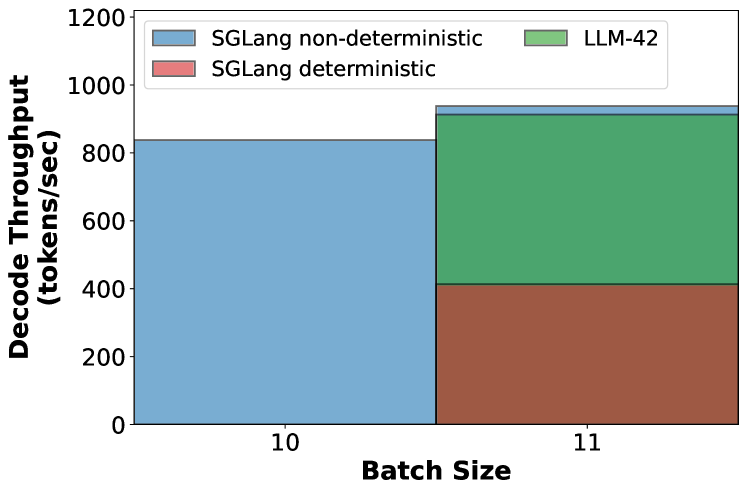
## Bar Chart: Decode Throughput Comparison by Batch Size and Model
### Overview
The chart compares decode throughput (tokens/second) across three models (SGLang non-deterministic, SGLang deterministic, LLM-42) at two batch sizes (10 and 11). Throughput is measured on the y-axis (0–1200 tokens/sec), while batch size is on the x-axis (10 and 11). The legend in the top-left corner maps colors to models: blue (SGLang non-deterministic), red (SGLang deterministic), and green (LLM-42).
### Components/Axes
- **X-axis (Batch Size)**: Labeled "Batch Size" with ticks at 10 and 11.
- **Y-axis (Decode Throughput)**: Labeled "Decode Throughput (tokens/sec)" with increments of 200 up to 1200.
- **Legend**: Positioned in the top-left corner, with three entries:
- Blue: SGLang non-deterministic
- Red: SGLang deterministic
- Green: LLM-42
### Detailed Analysis
- **Batch Size 10**:
- **SGLang non-deterministic (blue)**: Dominates with ~800 tokens/sec.
- **SGLang deterministic (red)**: Not visible (implied 0 tokens/sec).
- **LLM-42 (green)**: Not visible (implied 0 tokens/sec).
- **Batch Size 11**:
- **SGLang non-deterministic (blue)**: Minimal throughput (~10 tokens/sec).
- **SGLang deterministic (red)**: ~400 tokens/sec.
- **LLM-42 (green)**: ~800 tokens/sec.
### Key Observations
1. **SGLang non-deterministic** shows a drastic drop in throughput when batch size increases from 10 to 11 (~800 → ~10 tokens/sec).
2. **SGLang deterministic** and **LLM-42** maintain stable performance at batch size 11 (~400 and ~800 tokens/sec, respectively).
3. No data is reported for SGLang deterministic and LLM-42 at batch size 10.
### Interpretation
The data suggests that **SGLang non-deterministic** is highly sensitive to batch size increases, experiencing a near-collapse in efficiency at batch size 11. In contrast, **SGLang deterministic** and **LLM-42** demonstrate robustness, maintaining significant throughput even at larger batch sizes. This implies that non-deterministic processing may face scalability challenges in high-throughput scenarios, while deterministic and LLM-42 architectures are better optimized for larger batches. The absence of data for deterministic and LLM-42 at batch size 10 raises questions about whether these models were tested at that configuration or if the results were intentionally omitted.