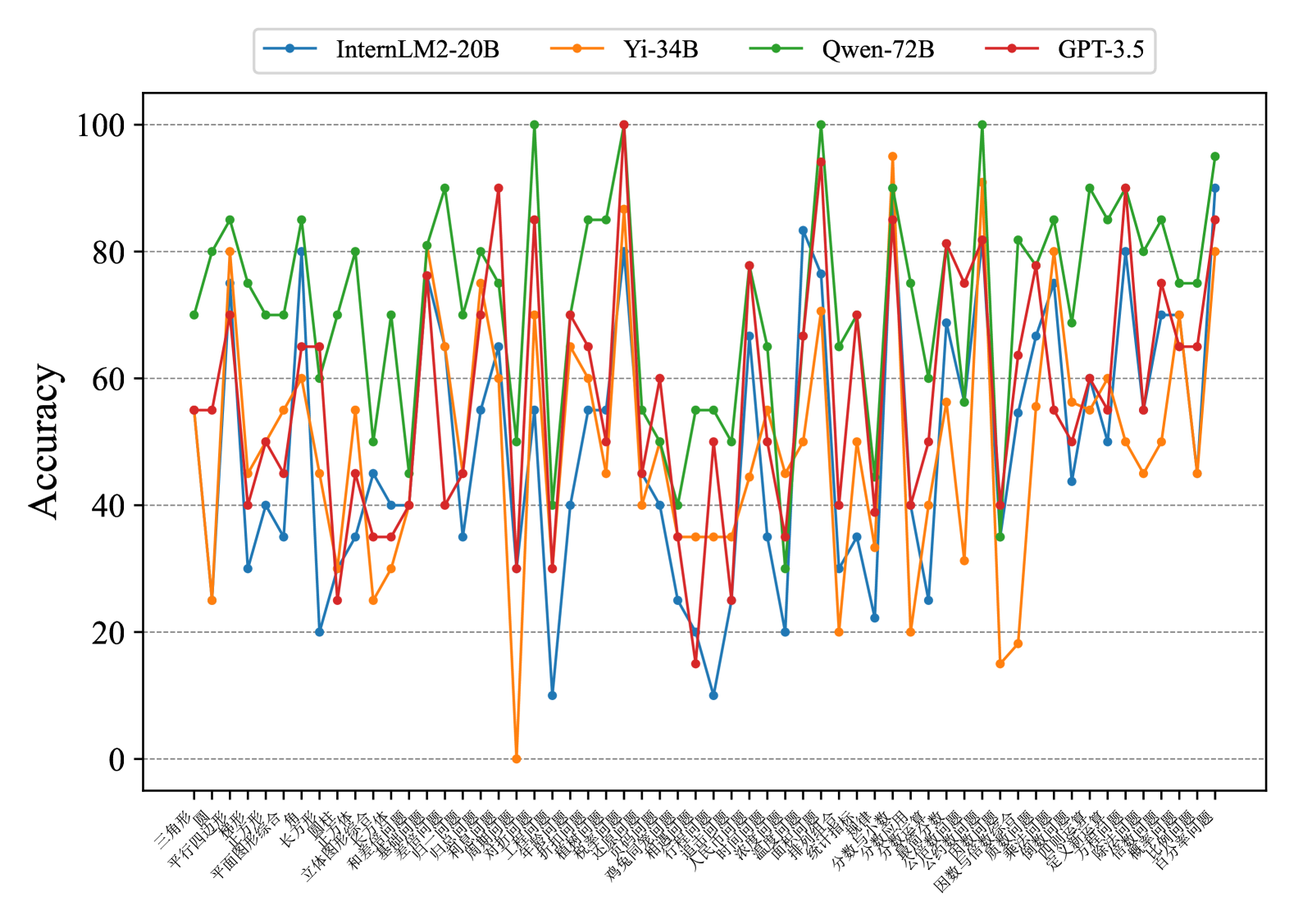
## Multi-Line Chart: Accuracy of Four AI Models Across Chinese Math Problem Categories
### Overview
This image is a multi-line chart comparing the accuracy (0-100%) of four large language models (LLMs) across a wide range of Chinese mathematics problem categories. The chart is dense, with each model's performance plotted as a distinct colored line connecting data points for each category on the x-axis.
### Components/Axes
* **Chart Type:** Multi-line chart with markers.
* **Y-Axis:**
* **Label:** "Accuracy"
* **Scale:** Linear, from 0 to 100.
* **Major Ticks/Gridlines:** At 0, 20, 40, 60, 80, 100.
* **X-Axis:**
* **Label:** None explicit. Contains category labels in Chinese.
* **Categories (Left to Right):** 三角形, 平行四边形, 梯形, 长方形, 平面图形综合, 长方体, 圆柱, 立体图形综合, 和差倍问题, 基础应用题, 发展问题, 归一问题, 和周问题, 对称问题, 工程问题, 折线统计图, 扇形统计图, 概率问题, 鸡兔同笼问题, 行程问题, 人民币问题, 温度问题, 面积问题, 统计与概率, 分数与小数, 分数的意义与性质, 公因数与公倍数, 公约数问题, 因数与倍数综合, 乘法问题, 定义新运算问题, 方程与解方程, 解比例问题, 比例问题, 百分数问题.
* **Legend:**
* **Position:** Top center, above the plot area.
* **Items:**
1. **InternLM2-20B:** Blue line with circle markers.
2. **Yi-34B:** Orange line with diamond markers.
3. **Qwen-72B:** Green line with pentagon markers.
4. **GPT-3.5:** Red line with square markers.
### Detailed Analysis
**Trend Verification & Data Extraction (Approximate Values):**
The chart shows high volatility, with accuracy swinging dramatically between categories for all models. No single model consistently dominates across all topics.
* **InternLM2-20B (Blue, Circles):**
* **Trend:** Highly variable, often in the middle-to-lower range compared to others. Shows several deep troughs.
* **Notable Points:** Low points around 10-20% in categories like "和差倍问题" and "行程问题". Peaks near 80% in "平面图形综合" and "百分数问题".
* **Yi-34B (Orange, Diamonds):**
* **Trend:** Also highly variable, with extreme highs and lows. Notably, it hits 0% in one category.
* **Notable Points:** Hits 0% in "对称问题". Has very high peaks (~95%) in "分数与小数" and "因数与倍数综合". Generally performs poorly on geometry and word problems.
* **Qwen-72B (Green, Pentagons):**
* **Trend:** Appears to be the most consistently high-performing model, frequently occupying the top position. Its line is often the upper envelope of the chart.
* **Notable Points:** Reaches or nears 100% in several categories: "平面图形综合", "折线统计图", "扇形统计图", "分数与小数". Its lowest points are still relatively high, rarely dropping below 40%.
* **GPT-3.5 (Red, Squares):**
* **Trend:** Volatile, often competing with Qwen-72B for the top spot but with more pronounced dips.
* **Notable Points:** Hits 100% in "扇形统计图". Has strong performance in statistics and probability topics. Shows a significant dip below 20% in "行程问题".
### Key Observations
1. **Category Difficulty:** Certain categories appear universally challenging, causing sharp drops for all models. Examples include "行程问题" (Travel Problems) and "鸡兔同笼问题" (Chicken-and-Rabbit Cage Problems), where most models score below 60%.
2. **Model Strengths:**
* **Qwen-72B** excels in geometry ("平面图形综合"), statistics ("折线/扇形统计图"), and number theory ("分数与小数").
* **GPT-3.5** shows particular strength in statistics and probability.
* **Yi-34B** has isolated high peaks in specific number theory topics but is unreliable.
3. **Model Weaknesses:** All models struggle with complex word problems ("行程问题", "鸡兔同笼问题") and certain applied concepts.
4. **Extreme Outlier:** Yi-34B's 0% accuracy in "对称问题" (Symmetry Problems) is a critical failure point.
### Interpretation
This chart provides a granular benchmark of LLM capabilities in Chinese elementary and middle school mathematics. The data suggests:
* **No Universal Solver:** No single model is superior across all mathematical domains. Model selection should be task-specific.
* **Specialization vs. Generalization:** Qwen-72B demonstrates the most robust generalization, maintaining high accuracy across diverse topics. Yi-34B appears more specialized, with extreme variance indicating potential gaps in its training data or reasoning for certain problem types.
* **The Challenge of Applied Math:** The consistent poor performance on word problems ("行程", "鸡兔同笼") highlights a persistent weakness in LLMs: translating textual narratives into formal mathematical models and solving them step-by-step. This requires robust reasoning and planning, not just pattern recognition.
* **Data for Improvement:** The specific categories where models fail (e.g., GPT-3.5 on "行程问题", Yi-34B on "对称问题") provide clear targets for diagnostic analysis and future model training or fine-tuning.
**Language Note:** All category labels on the X-axis are in Chinese (Simplified). English translations have been provided in the Components/Axes section.